AudioSep
Open domain audio source separation model based on natural language query
Product Details
AudioSep is an open-domain audio source separation model based on natural language query. It consists of two key components: text encoder and separation model. We train AudioSep on a large-scale multi-modal dataset and extensively evaluate its capabilities on a number of tasks, including audio event separation, instrument separation, and speech enhancement. AudioSep demonstrates strong separation performance and impressive zero-shot generalization capabilities using audio titles or text labels as queries, significantly outperforming previous sound separation models for audio queries and language queries. To ensure the reproducibility of this work, we will release the source code, evaluation benchmarks, and pretrained models.
Main Features
Target Users
Suitable for the field of audio separation and can be used in audio processing, audio editing and other fields
Examples
Separate guitar sounds in audio using AudioSep
Separate vocals in audio using AudioSep
Separate piano sounds in audio using AudioSep
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

Draw an Audio
Draw an Audio is an innovative video-to-audio synthesis technology that generates high-quality synchronized audio based on video content through multi-instruction control. This technology not only improves the controllability and flexibility of audio generation, but also can produce mixed audio in multiple stages, showing a wider range of practical application potential.

Udio v1.5
Udio v1.5 is an advanced version of the music creation platform. It has made many improvements based on v1, including improving sound quality, providing tone control, improving global language support, etc. It generates 48kHz stereo tracks, providing clearer sound quality and better instrument separation. In addition, Udio v1.5 also provides a series of new features, such as dedicated creation pages, audio track downloads, audio to audio mixing, shareable lyric videos, etc., aiming to further empower music creators.

ElevenLabs text-to-sound API
ElevenLabs' text-to-sound effects API allows users to generate high-quality sound effects based on short text descriptions. These sound effects can be applied to a variety of scenarios such as game development and music production applications. The API utilizes advanced audio synthesis technology to dynamically generate sound effects based on text prompts, providing users with an innovative sound design tool.

ComfyUI-StableAudioSampler
ComfyUI-StableAudioSampler is an audio sampler plug-in integrated in the ComfyUI node. It allows users to generate audio and output raw bytes and sample rates, supports all raw Stable Audio Open parameters, and can save audio to files. This plugin is open source and actively developed to provide music makers with an easy-to-use and powerful tool.

ElevenLabs Text to Sound Effects
Text to Sound Effects is the latest AI audio model developed by ElevenLabs, which can generate various sound effects, short music tracks, soundscapes and character sounds based on text prompts. It represents a major innovation in audio production, providing film and television studios, video game developers, and social media content creators with the tools to generate rich, immersive soundscapes quickly, affordably, and at scale. Through a partnership with Shutterstock and leveraging licensed tracks from its extensive audio library, the product has been finely tuned to create a versatile new tool for modern creators.

Amped Studio
Amped Studio is an online music production platform that provides functions such as music creation, beat production, audio editing, sound recording and engineering. Find all the tools you need to create music here!

TiangongSkyMusic
The large-scale AI music generation model "Tiangong SkyMusic" built on the super large model of Kunlun Wanwei's "Tiangong 3.0" supports high-quality AI music generation, vocal synthesis, lyrics paragraph control, multiple music styles and intelligent musical expression. It is currently open for free beta testing to help users better create music and express emotions.

Adobe Project Music GenAI Control
Project Music GenAI Control developed by Adobe Research is an experimental AI music generation and editing tool that allows creators to generate music through text prompts and provide granular editing control to meet specific needs.

MusicFX
MusicFX is an online platform that allows users to create music. It provides a rich sound effect library and creation tools. Users can choose different sound effect materials and create their own original music through simple operations such as dragging and combining. This platform is suitable for music lovers of all ages. No professional music knowledge is required, and you can also create online and experience the fun of music creation.
FreGrad
FreGrad is a lightweight and fast frequency-aware diffusion vocoder designed to generate realistic audio. Its framework includes discrete wavelet transform, frequency-aware dilated convolution and a series of techniques to enhance the quality of model generation. In experiments, compared with the baseline model, FreGrad improved training speed by 3.7 times, inference speed by 2.2 times, and reduced model size by 0.6 times (only 1.78 million parameters) without sacrificing output quality.

Ultimate Vocal Remover GUI
Ultimate Vocal Removal GUI is a vocal removal tool using deep neural network technology. Its core developers trained all provided models except Demucs v3 and v4 4-channel models. The application uses advanced source separation models to remove vocals from audio files. No additional prerequisites are required to run effectively. Available for Windows 10 and above.
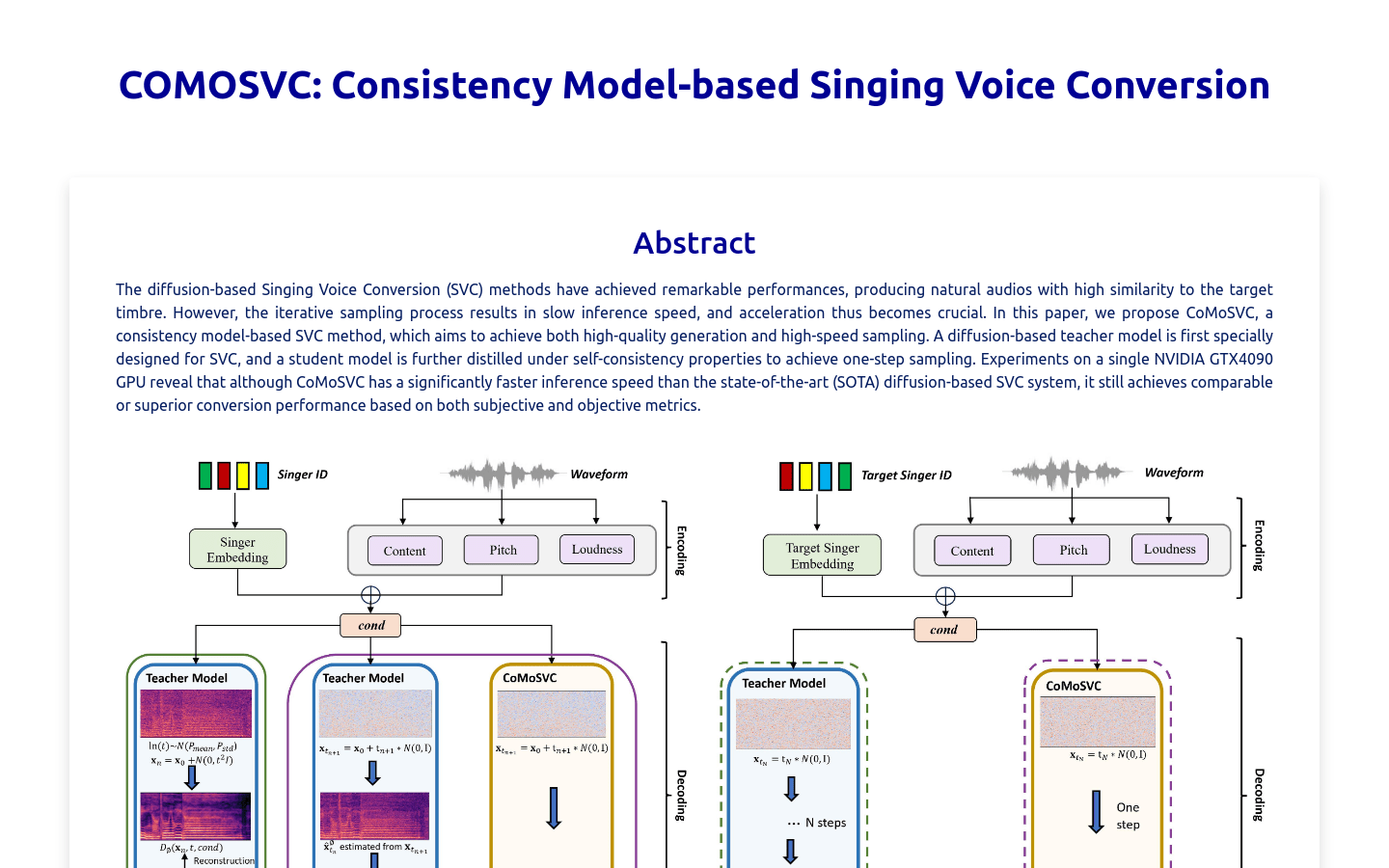
COMOSVC
COMOSVC is a singing pitch conversion technology based on the consistency model, which can achieve high-quality conversion effects and fast sampling speed. This technology first designs a diffusion-based teacher model for the singing pitch conversion task, and then performs knowledge distillation through self-consistency attributes to achieve one-step sampling. Compared with current state-of-the-art dispersion-based singing pitch conversion systems, COMOSVC achieves significantly faster inference speeds while maintaining comparable or even superior conversion performance.

music-fx
Music FX is an online music production tool that provides rich sound effects and sound materials that users can use to create various types of music. It supports adjusting pitch, rhythm and volume, and can also add reverb, echo and other sound effects. Whether you want to create a soothing atmosphere or an adventurous one, Music FX has what you need.

Blerp Sound Memes. AI TTS Voices Emotes GIFS
Blerp is an AI TTS voice meme, emoticon GIF and voice prompt product. It provides the most interesting AI TTS alerts, expressions and sound packs for chat and live streaming communities. Viewers can stream the best sounds and AI TTS voices on any streaming platform and attach emoticons and GIFs to them. As a viewer, you can also collect channel points on your favorite streamers and play your own WalkOn Sounds. Anchors can set their own sounds and use WalkOn Subscriber sounds on any supported extension platform.
Polymath
Polymath uses machine learning to convert any music library (such as from your hard drive or YouTube) into a library of music production samples. This tool can automatically split the song into beat, bass and other track parts, quantize them to the same speed and beat format (for example, 120bpm), analyze the music structure (for example, chorus, chorus, etc.), key (for example, C4, E3, etc.) and other information (timbre, loudness, etc.), and convert the audio to MIDI. The result is a searchable sample library that streamlines the workflow of music producers, DJs, and ML audio developers.

MusicGen Remixer
MusicGen Remixer is a music remix model based on MusicGen Chord. It can receive an audio file as input and use the MusicGen Chord generator to reset it to a different style of music. The model supports functions such as multi-band diffusion, rhythm synchronization, and chord chroma, and can control the style and diversity of the generated music by adjusting parameters.