
Product Details
Jamit is the world's first Podcast 3.0 platform, providing distributed hosting, global coverage, interactive rewards and unique NFT experiences. Users can discover and listen to stories from different fields on Jamit, create and grow their own communities, and enjoy their independence as Jamit creators and owners.
Main Features
Target Users
Users can listen to different types of stories on Jamit, and creators can develop their own communities and interact with audiences on the platform.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

BPM Finder
BPM Finder is an advanced BPM analysis tool that can accurately detect the rhythm of any audio source, with three powerful analysis modes. It provides music creators and DJs with professional BPM detection capabilities for accurate rhythm analysis.

Free AI Vocal Remover & Stem Splitter
Music and Voice Separation is an online service that uses advanced AI technology to separate vocals and accompaniment in music. Its main advantages are that it is fast, free and requires no login, helping users to easily separate different elements in their music.
Music Eleven AI
Music Eleven AI is an AI music generator that uses advanced machine learning models to generate complete musical compositions, including melody, harmony, rhythm and vocals, from text descriptions. The product is commercially licensed and supports more than 30 music styles, making it suitable for creators, musicians and businesses. The price is divided into three plans: Starter, Creator and Professional.
Singify Vocal Remover
Singify Vocal Remover is a tool that uses advanced AI technology to extract vocals and instruments from music. It accurately extracts a song's vocals and isolates individual parts such as drums, bass, piano, electric guitar, acoustic guitar, and synthesizers. The tool is free and easy to use, retains original audio details, and supports multiple audio output formats.

Dubnote
Dubnote is a session recording application designed for musicians to help them capture and organize musical ideas. Users can organize recordings into folders, automatically split into sections, and mark key moments with emojis or notes. The main benefit of this app is to help musicians better manage and preserve creative inspiration.
voicss
Voicss is an AI audio track remover that can intelligently separate vocals and background music in music. It is suitable for music editing, karaoke production and other fields without downloading software.
Echovox Studio
Echovox Studio is a powerful music production software with advanced recording and mixing features that can be used to produce a variety of music genres. Its main advantages are its intuitive and easy-to-use interface and rich audio processing tools.

Audio-SDS
Audio-SDS is a framework that applies Score Distillation Sampling (SDS) concepts to audio diffusion models. The technology enables leveraging large pre-trained models for a variety of audio tasks, such as physically guided impact sound synthesis and cue-based source separation, without the need for specialized datasets. Its main advantage is that through a series of iterative optimizations, complex audio generation tasks become more efficient. This technology has broad application prospects and can provide a solid foundation for future audio generation and processing research.

AudioX
Audiox is a tool that uses AI technology to generate professional audio. No music knowledge is required to quickly create stunning music and sound effects. Its main advantages include convenient creation, excellent sound quality, and simple use. It is suitable for music production, video production, sound effect design and other fields.

Soundlabs AI
Soundlabs AI is an audio tool for music producers focused on real-time sound and instrument transformation. It uses advanced AI technology to convert users' voices into high-quality virtual singer or instrument sounds, seamlessly integrated into any digital audio workstation (DAW). Key advantages of this technology include real-time conversion, high-quality audio output, and a rich library of timbre models. Soundlabs AI not only increases the flexibility of music creation, but also provides creators with unlimited creative possibilities, whether in pop, electronic music or other genres. Its price positioning is clear and it provides a variety of purchase options, including one-time purchases and subscription services, to meet the needs of different users.

GenSFX
GenSFX is a sound effect generation tool based on advanced AI technology. It provides users with efficient and convenient sound effect creation solutions by converting text descriptions into professional sound effects. Its main advantages include: no professional sound effect production knowledge is required, users only need to enter a text description to quickly generate the required sound effects; the generated sound effects are of high quality and can meet the needs of different scenarios; the operation is simple and no complicated settings are required. This product is mainly aimed at content creators, game developers and other user groups who need customized sound effects, helping them save time and costs and improve creation efficiency. GenSFX currently provides free services to users, lowering the threshold for sound effect creation and enabling more people to easily obtain high-quality sound effects.
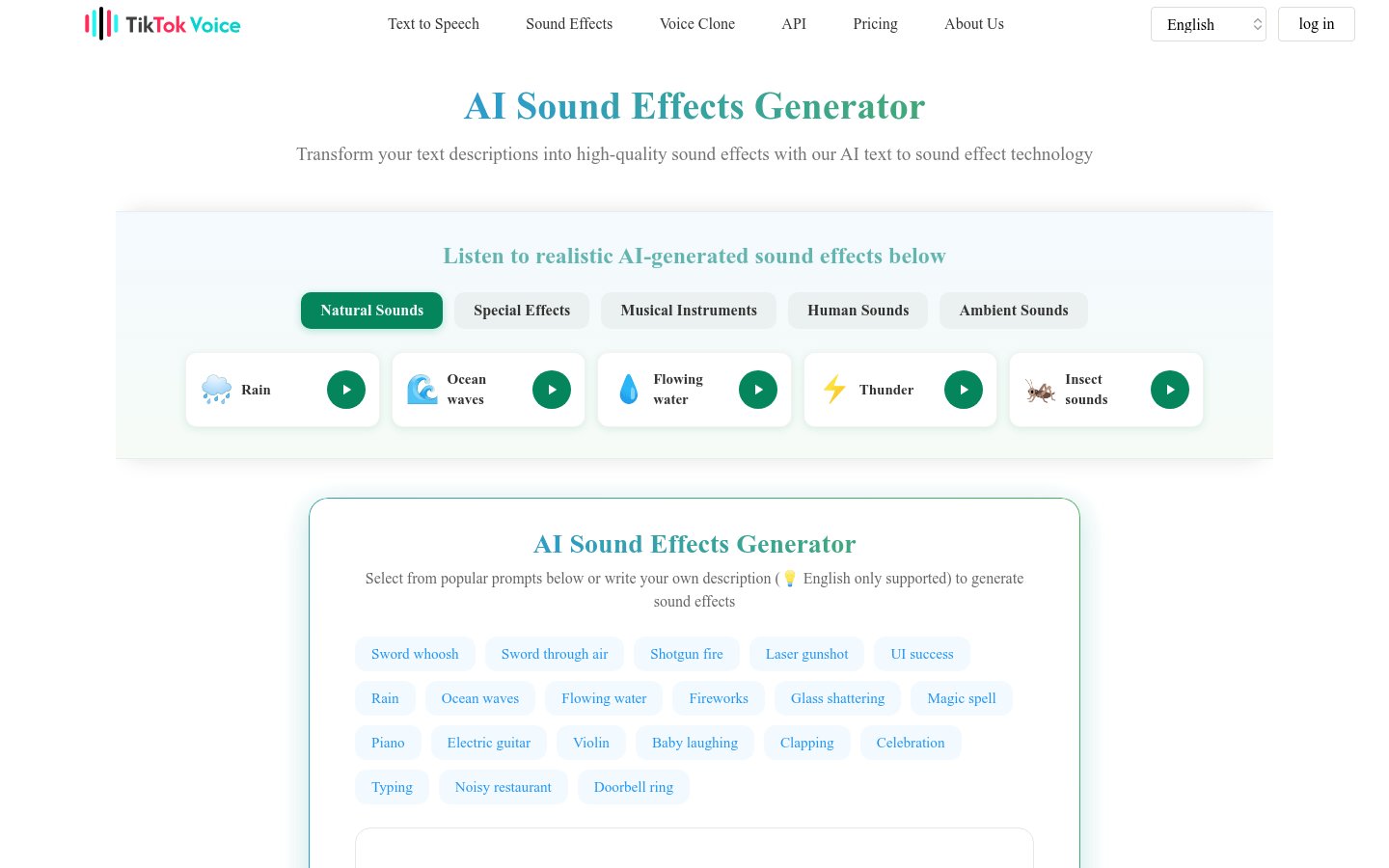
TikTokVoice AI Sound Effect Generator
AI Sound Effect Generator is a revolutionary tool that uses advanced AI technology to convert written descriptions into custom sound effects. The technology combines natural language processing and neural audio synthesis to produce high-quality output. The system uses deep learning models trained on large audio data sets to understand complex audio features and generate corresponding effects. It's for content creators, game developers, and audio professionals who need quick access to custom sound effects. AI Sound Effect Generator processes detailed description and contextual information to create detailed, layered audio effects to match your creative vision. Whether it's ambient ambience, mechanical noise, musical elements or abstract effects, our systems generate them accurately and with fidelity. This method of audio generation offers creative possibilities through the power of artificial intelligence.

AIVocal
AIVocal is an online vocal removal tool based on artificial intelligence technology. It can remove vocals from any song in a short time, create accompaniment tapes, separate instrument tracks, and improve music production efficiency. The product meets the needs of music producers, content creators and cover artists with its high efficiency, precision and ease of use. AIVocal supports a variety of audio formats, such as MP3, WAV and FLAC, making it suitable for professional music production and daily entertainment use.

Sketch2Sound
Sketch2Sound is a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals (loudness, brightness, pitch) as well as text cues. The model can be implemented on any text-to-audio latent diffusion transformer (DiT) and requires only 40k steps of fine-tuning and a separate linear layer per control, making it more lightweight than existing methods such as ControlNet. The main advantages of Sketch2Sound include the ability to synthesize arbitrary sounds from sound imitations and to follow the general intent of the input controls while maintaining input text prompts and audio quality. This enables sound artists to create sounds by combining the semantic flexibility of text cues with the expressiveness and precision of vocal gestures or vocal imitations.

Vocal Remover Online
Vocal Remover Online is a website based on deep learning technology that can separate vocals and accompaniment from audio or video. This technology is useful for music producers, video makers, and karaoke enthusiasts because it can easily separate accompaniment and vocals, allowing users to use it for music creation, video editing, or personal entertainment. The product provides free basic services and may charge a fee for advanced features and batch processing.

ComfyUI-MMAudio
ComfyUI-MMAudio is a plug-in based on ComfyUI that allows users to utilize the MMAudio model for audio processing. The main advantages of this plug-in are its ability to provide high-quality audio generation and processing capabilities, support for multiple audio models, and easy integration into existing audio processing pipelines. Product background information shows that it was developed by kijai and is open source and can be found on GitHub. Currently, the plug-in is mainly aimed at technology enthusiasts and audio processing professionals and can be used for free.