ZipLoRA
Any theme, any style, effectively merge LoRAs

Product Details
ZipLoRA is a method that effectively merges independently trained style and topic LoRAs to achieve content generation under any user-provided topic and style. Through optimized methods, ZipLoRA is able to retain the content and style-generating properties of original LoRAs, while being able to re-contextualize reference objects and have the ability to control the degree of style. This approach achieves significant improvements in thematic and stylistic fidelity.
Main Features
Target Users
Used to generate content in any user-supplied theme and style
Examples
Generate stylized images of specific objects
Recontextualize reference objects
Control the level of style of generated content
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools
Fogsight
Fogsight is an innovative animation engine that leverages large language models to generate vivid animations. Not only does it support multiple languages, it can also generate high-level narrative animations based on user input, and is suitable for education, entertainment and creative fields. Fogsight focuses on user experience, allowing interaction with AI through a simple interface to quickly generate the required animated content.

MuseSteamer AI
MuseSteamer AI is a breakthrough multimedia intelligence engine that transforms concepts and visuals into advanced content. The platform achieves a VBench performance metric of 89.38% through innovative computational creativity, turning your ideas into premium content.

Next Apps
Next Apps Lab is a creative studio focused on building innovative user-friendly apps. They experiment, design and develop intuitive solutions that simplify tasks and turn ideas into reality.

MeshifAI
MeshifAI is an advanced text-to-3D model generation platform designed to help developers quickly integrate high-quality 3D generation capabilities into applications, games, and websites. With its powerful AI technology, users only need to enter a description to generate a realistic 3D model, greatly simplifying the 3D design process. The platform is easy to use and suitable for a variety of development needs.

Hunyuan3D 2.0
Hunyuan3D 2.0 is an advanced large-scale 3D synthesis system launched by Tencent, focusing on generating high-resolution textured 3D assets. The system includes two basic components: the large-scale shape generation model Hunyuan3D-DiT and the large-scale texture synthesis model Hunyuan3D-Paint. It provides users with a flexible 3D asset creation platform by decoupling the challenges of shape and texture generation. This system surpasses existing open source and closed source models in terms of geometric details, conditional alignment, texture quality, etc., and is extremely practical and innovative. At present, the inference code and pre-training model of this model have been open sourced, and users can quickly experience it through the official website or Hugging Face space.

Utopia
Utopia is a personalized character creation platform dedicated to creating a new generation of super-humanoid AI agents. Its main advantages include more controllability, anthropomorphism, and safety. Background information shows that the product focuses on user participation in creation and is positioned to provide highly personalized role models.

DreamMat
DreamMat is an innovative model that generates Physically Based Rendering (PBR) materials for 3D meshes based on text prompts. It solves the shortcomings of existing 2D diffusion models in material decomposition and generates high-quality PBR materials that are consistent with the given geometry and lighting environment and have no built-in shadow effects. This technology is of great significance for downstream tasks such as gaming and film production, as it significantly improves rendering quality and enhances the user's visual experience.

CSM 3D Viewer
CSM 3D Viewer is an online 3D model viewer that allows users to view and interact with 3D models on the web. It supports a variety of 3D file formats and provides basic operations such as rotation and scaling, as well as more advanced viewing functions. CSM 3D Viewer is suitable for designers, engineers and 3D enthusiasts, helping them display and share 3D works more intuitively.

StrokeNUWA
StrokeNUWA is a pioneering work that explores better visual representation of "partition markup" on vector graphics that is visually semantically rich, naturally compatible with LLMs, and highly compressible. Equipped with partition markers, StrokeNUWA significantly outperforms traditional LLM-based and optimization-based methods on various metrics for vector graphics generation tasks. In addition, StrokeNUWA achieves up to 94x acceleration in inference speed and has an excellent SVG code compression ratio of 6.9% compared to previous methods.
InternLM-XComposer2
InternLM-XComposer2 is a leading visual language model, good at free-form text image synthesis and understanding. The model not only understands traditional visual language, but also expertly constructs intertwined text-image content from a variety of inputs, such as outlines, detailed text specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) approach that specifically applies additional LoRA parameters to image tagging to preserve the integrity of pre-trained language knowledge and achieve a balance between precise visual understanding and literary composition of texts. Experimental results show that InternLM-XComposer2 based on InternLM2-7B is superior in generating high-quality long text multi-modal content, as well as its excellent visual language understanding performance in various benchmark tests, not only significantly better than existing multi-modal models, but also on par with or even exceeding GPT-4V and Gemini Pro in some evaluations. This highlights its excellent capabilities in the field of multi-modal understanding. The InternLM-XComposer2 series of models has 7B parameters and is publicly available at https://github.com/InternLM/InternLM-XComposer.

Stable Zero123
Stable Zero123 is an in-house trained model for view-conditioned image generation. Stable Zero123 produces significantly improved results compared to its previous cutting-edge technology, Zero123-XL. It achieves this goal through three key innovations: 1. An improved training dataset that is heavily filtered from the Objaverse, retaining only high-quality 3D objects and rendering more realistically than previous methods. 2. During training and inference, we provide the model with estimated camera angles. This elevation condition allows it to make more informed, higher quality predictions. 3. Pre-computed datasets (pre-computed latent variables) and an improved data loader that supports higher batch sizes, coupled with the first innovation, make training 40 times more efficient than Zero123-XL. The model is now available on Hugging Face for researchers and non-commercial users to download and experiment with.

Story-to-Motion
Story-to-Motion is a brand new task that takes a story (top green area) and generates actions and trajectories that match the text description. The system utilizes modern large-scale language models as text-driven motion schedulers to extract a sequence of (text, position) pairs from long texts. It also develops a text-driven motion retrieval scheme that combines classical motion matching with motion semantics and trajectory constraints. In addition, it is designed with a progressive masking transformer to solve common problems in transition movements, such as unnatural postures and sliding steps. The system performs well in the evaluation of three different subtasks: trajectory following, temporal action combination and action blending, outperforming previous action synthesis methods.
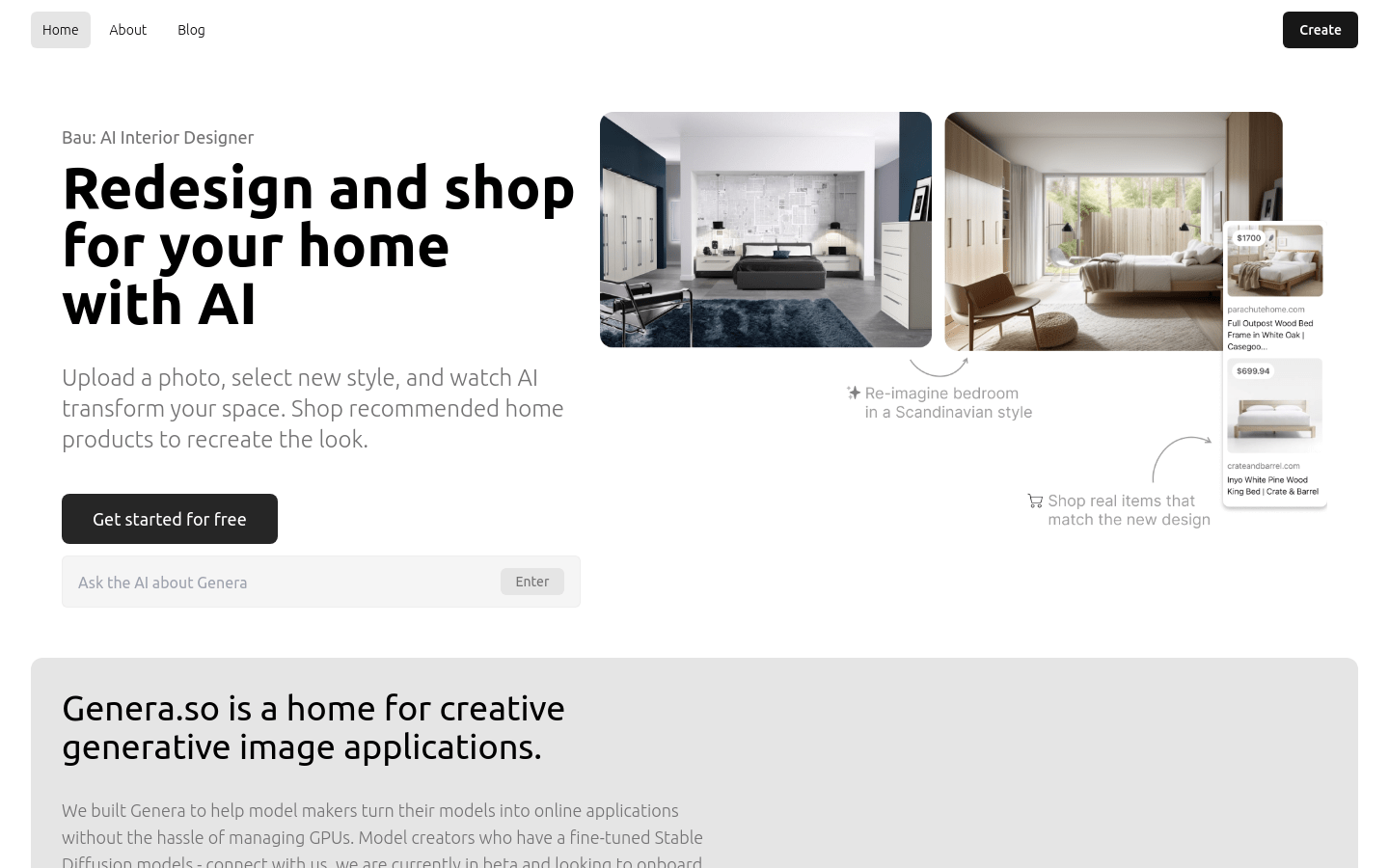
Genera.so
Genera.so is a platform that powers creative generative imaging applications. We built Genera to help model makers turn their models into online applications without the hassle of managing GPUs. If you have a fine-tuned stable diffusion model, please contact us, we are currently in beta and looking for more models.