free text Into Speech
Multilingual text-to-speech online platform

Product Details
Free Text to Speech Online Converter is a multi-language text-to-speech online platform. It supports more than 20 languages, has natural pronunciation, is free to use without registration, and has fast conversion speed.
Main Features
Target Users
It can be used to convert text content into speech to facilitate dictation, reading, learning and other scenarios.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools
Huxe
Huxe is a product that turns everyday information into personalized audio intelligence. Its importance lies in providing users with a convenient and efficient way to obtain information, allowing users to easily obtain the information they need even in scenarios where they cannot see the screen. The main advantages include personalized customization, strong interactivity, and the ability to convert various questions into audio explanations. The product background may be to meet people's needs for convenient information acquisition in fast-paced lives. There is no price information mentioned, but judging from the content, it may be free to use. The product is positioned to help users obtain information of interest in a timely manner without scrolling the screen for a long time in commuting, exercising, resting and other scenarios.

Katalog
Katalog is a tool that broadcasts articles through AI voice. It uses ultra-realistic AI voices to read your saved articles, providing a top-notch listening experience. Katalog is still free to use in the public beta phase, and free and paid versions may be launched in the future.
FlowSpeech
FlowSpeech is a free AI podcast generator that uses the latest speech synthesis technology to convert text into natural human voices, suitable for various user needs. It supports input in multiple formats, including PDF, TXT, etc., allowing users to quickly obtain information. Provides a variety of subscription options to help creators create podcasts more efficiently.

notigo.ai
Notigo is an AI real-time meeting summary generator that can automatically generate meeting summaries to help users no longer miss important content. Its main benefits include high-quality notes, structured content, precise summaries, multi-language support, and more.

Spark-TTS
Spark-TTS is an efficient text-to-speech synthesis model based on a large language model with the characteristics of single-stream decoupled speech tokens. It leverages the power of large language models to reconstruct audio directly from code predictions, omitting additional acoustic feature generation models, thereby increasing efficiency and reducing complexity. The model supports zero-shot text-to-speech synthesis and is able to switch scenarios across languages and codes, making it ideal for speech synthesis applications that require high naturalness and accuracy. It also supports virtual voice creation, and users can generate different voices by adjusting parameters such as gender, pitch, and speaking speed. The background of this model is to solve the problems of low efficiency and high complexity in traditional speech synthesis systems, aiming to provide efficient, flexible and powerful solutions for research and production. Currently, the model is mainly geared toward academic research and legitimate applications, such as personalized speech synthesis, assistive technology, and language research.

Llasa
Llasa is a text-to-speech (TTS) basic model based on the Llama framework, specially designed for large-scale speech synthesis tasks. The model is trained using 160,000 hours of labeled speech data and has efficient language generation capabilities and multi-language support. Its main advantages include powerful speech synthesis capabilities, low inference cost, and flexible framework compatibility. This model is suitable for education, entertainment and business scenarios and can provide users with high-quality speech synthesis solutions. The model is currently available for free on Hugging Face, aiming to promote the development and application of speech synthesis technology.

LLaDA
LLaDA is a new type of diffusion model that generates text through the diffusion process, which is different from the traditional autoregressive model. It excels in language generation scalability, instruction following, contextual learning, conversational capabilities, and compression capabilities. Developed by researchers from Renmin University of China and Ant Group, the model is 8B in size and trained entirely from scratch. Its main advantage is that it can flexibly generate text through the diffusion process and support multiple language tasks, such as mathematical problem solving, code generation, translation and multi-turn dialogue. The emergence of LLaDA provides a new direction for the development of language models, especially in terms of generation quality and flexibility.

Lemonfox.ai Text-to-Speech API
Lemonfox.ai Text-to-Speech API is an API service focusing on text-to-speech (TTS). It uses advanced AI technology to quickly convert text into natural and smooth speech, supports multiple languages and accents, and is suitable for a variety of scenarios, such as voice broadcasting, audiobook production, etc. Its main advantages include low cost, high quality, and easy integration, which can help enterprises or developers quickly implement voice functions and improve user experience. This product is positioned as an efficient and economical TTS solution for enterprises and developers, with reasonable price, free trial and high cost performance.

IndexTTS
IndexTTS is a GPT-style text-to-speech (TTS) model, mainly developed based on XTTS and Tortoise. It can correct the pronunciation of Chinese characters through pinyin and control pauses through punctuation. This system introduces a character-pinyin hybrid modeling method in the Chinese scene, which significantly improves training stability, timbre similarity, and sound quality. Additionally, it integrates BigVGAN2 to optimize audio quality. The model was trained on tens of thousands of hours of data and outperformed currently popular TTS systems such as XTTS, CosyVoice2, and F5-TTS. IndexTTS is suitable for scenarios that require high-quality speech synthesis, such as voice assistants, audiobooks, etc. Its open source nature also makes it suitable for academic research and commercial applications.

ElevenReader Publishing
ElevenReader Publishing is an innovative platform launched by ElevenLabs that uses AI audio models to transform books into high-quality audiobooks. It solves the problems of high cost and complex process of traditional audiobook production, providing authors with a fast, free and global distribution solution. The platform supports the import of multiple file formats, and users can preview the audio and select their favorite AI voice. Additionally, it provides audience reporting and analytics features to help authors better understand their audiences. Its main advantages are zero cost, rapid generation and global distribution, making it suitable for independent authors and publishers.
ElevenLabs Studio
ElevenLabs Studio is a platform focused on audio content creation, using advanced artificial intelligence technology to convert text content into high-quality audio. Its main advantages include supporting multiple file formats, providing a rich voice library, and being able to adjust voice expressions based on emotion and context. The platform is suitable for scenarios such as audiobook production and podcast creation, and can help creators efficiently generate audio content and improve creation efficiency and quality. Its pricing strategy may vary depending on user needs and usage scenarios. For specific prices, please refer to the pricing page of the official website.
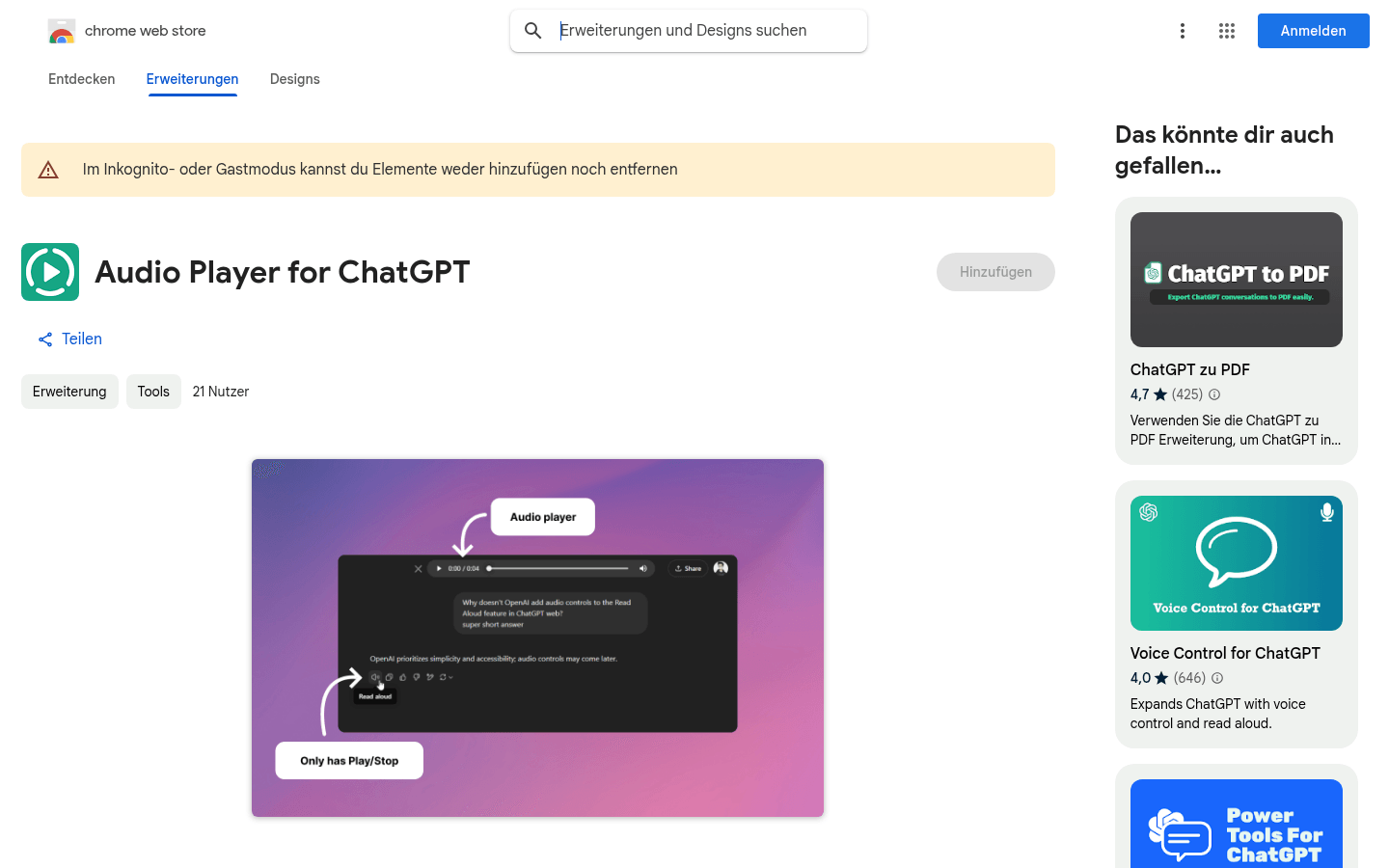
Audio player for ChatGPT
This product is a Chrome extension designed to improve the speaking functionality of ChatGPT. By displaying an audio player, users can more conveniently control the reading process, such as pausing, fast forwarding, etc. It is mainly aimed at users with poor vision or who like to listen and read, helping them use ChatGPT more efficiently. The product is open source and users can choose to install extensions or manually integrate the code into their own script manager. Its free nature makes it highly accessible.

Zonos-v0.1-hybrid
Zonos-v0.1-hybrid is an open source text-to-speech model developed by Zyphra that generates highly natural speech based on text prompts. The model is trained on a large amount of English speech data, uses eSpeak for text normalization and phoneticization, and then predicts DAC tokens through a transformer or hybrid backbone network. It supports multiple languages, including English, Japanese, Chinese, French, and German, and provides fine-grained control over the speech rate, pitch, audio quality, and emotion of the generated speech. In addition, it has a zero-sample voice cloning function that requires only 5 to 30 seconds of voice samples to achieve high-fidelity voice cloning. The model runs faster on an RTX 4090 with a real-time factor of about 2x. It also comes with an easy-to-use grario interface and can be easily installed and deployed via a Docker file. Currently, the model is available on Hugging Face, and users can use it for free, but they need to deploy it themselves.

TurboTTS
TurboTTS is a text-to-speech tool based on advanced artificial intelligence technology. It can quickly convert written text into natural, lifelike speech, supporting up to 70 languages and more than 300 real speech types. The main advantages of this technology are its high-quality speech output, easy-to-use interface, and fast and efficient content generation capabilities. Its background information shows that the platform is used by more than 228,000 creators around the world, processes more than 50 million dubbing texts every day, and provides a 99.9% uptime guarantee and 98% user satisfaction. TurboTTS offers both free and paid plans suitable for both personal and professional users.

Sonofa
Sonofa is a product based on artificial intelligence technology that can convert various forms of reading content (such as text in web pages, PDF files, and pictures) into audio content in the form of podcasts. This technology leverages advanced text-to-speech (TTS) and natural language processing (NLP) capabilities to convert text content into natural and smooth speech, allowing users to access information without reading. The main advantage of this product is that it greatly improves the flexibility and efficiency of information acquisition, especially for those who are unable to read while commuting, exercising or leisurely. Sonofa’s background information shows that it aims to help users make better use of fragmented time and improve personal learning and work efficiency through innovative ways. Currently, the services provided by Sonofa may be paid services based on a subscription model, and the specific price and positioning have not yet been determined.

Kokoro TTS
Kokoro TTS is an AI model that focuses on text-to-speech. Its main function is to convert text content into natural and smooth speech output. This model is based on the StyleTTS 2 architecture and has 82 million parameters, which can provide efficient performance and low resource consumption while maintaining high-quality speech synthesis. Its multi-language support and customizable voice packages enable it to meet the needs of different users in a variety of scenarios, such as producing audiobooks, podcasts, training videos, etc. It is especially suitable for the education field to help improve the accessibility and attractiveness of content. In addition, Kokoro TTS is open source and free for users to use, which makes it significantly cost-effective.