Diffuse to Choose
Virtual try-on product image restoration model

Product Details
Diffuse to Choose is a diffusion-based image repair model mainly used in virtual try-on scenarios. It is able to preserve the details of reference items when repairing images and is capable of accurate semantic operations. By directly incorporating the detailed features of the reference image into the latent feature map of the main diffusion model, and combining perceptual losses to further preserve the details of the reference items, this model achieves a good balance between fast inference and high-fidelity details.
Main Features
Target Users
Diffuse to Choose is suitable for image restoration tasks in virtual try-on scenarios such as online shopping.
Examples
Fix images in virtual try-on app
Add missing details to product images
Perform semantic operations on images
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

FLUX.1-dev-Controlnet-Inpainting-Beta
FLUX.1-dev-Controlnet-Inpainting-Beta is an image inpainting model developed by Alimama's creative team. This model has significant improvements in the field of image inpainting, supporting direct processing and generation of 1024x1024 resolution without additional amplification steps, providing higher quality and more detailed output results. The model has been fine-tuned to capture and reproduce more detail of the repaired area and provide more precise control over the generated content with enhanced prompt interpretation.

FLUX.1-dev-Controlnet-Inpainting-Alpha
FLUX.1-dev-Controlnet-Inpainting-Alpha is an AI image repair model released by AlimamaCreative Team, specifically designed to repair and fill in missing or damaged parts of images. This model performs best at 768x768 resolution and is able to achieve high-quality image restoration. As an alpha version, it demonstrates advanced technology in the field of image restoration, and is expected to provide even more superior performance with further training and optimization.

FLUX-Controlnet-Inpainting
FLUX-Controlnet-Inpainting is an image repair tool based on the FLUX.1-dev model released by Alimama's creative team. This tool uses deep learning technology to repair images and fill in missing parts, and is suitable for image editing and enhancement. It performs best at 768x768 resolution and can provide high-quality image repair effects. The tool is currently in alpha testing stage and an updated version will be released in the future.

Fai-Fuzer
Fai-Fuzer is an image editing tool based on AI technology, which can achieve precise editing and control of images through advanced control network technology. The main advantage of this tool is its high flexibility and accuracy, which can be widely used in image repair, beautification, creative editing and other fields.
Diffree
Diffree is a text-guided image inpainting model that is able to add new objects to images through text descriptions while maintaining background consistency, spatial suitability, and object relevance and quality. By training on the OABench dataset, using a stable diffusion model and an additional mask prediction module, the model is uniquely able to predict the location of new objects, enabling object addition guided only by text.

SUPIR
SUPIR is a groundbreaking image inpainting method that leverages the power of generative priors and model expansion. Leveraging multi-modal techniques and advanced generative priors, SUPIR makes significant progress in intelligent and realistic image inpainting. As a key catalyst within SUPIR, model extensions significantly enhance its capabilities and demonstrate new potential for image restoration. We collected a dataset of 20 million high-resolution, high-quality images for model training, each accompanied by descriptive text annotations. SUPIR can repair images based on text prompts, broadening its application scope and potential. Furthermore, we introduce negative quality cues to further improve the perceived quality. We also develop a repair-guided sampling method to suppress the fidelity issues encountered in generative repair. The experiment proved SUPIR's excellent repair effect and its new ability to control repair through text prompts.
HandRefiner
The ControlNet-HandRefiner-pruned model is the fp16 version of the HandRefiner model after pruning and compression processing, which can perform hand image repair more quickly. This model uses a diffusion model for conditional image completion, which can accurately repair missing or deformed parts in hand images. This model has high compression rate and fast inference speed, and is very suitable for high-quality hand image restoration in resource-limited environments.

Personalized Restoration via Dual-Pivot Tuning
This paper proposes a simple and effective personalized image restoration method called dual-hub tuning. The method consists of two steps: 1) leveraging the conditional information in the encoder for personalization by fine-tuning the conditional generative model; 2) fixing the generative model and adjusting the parameters of the encoder to adapt to the enhanced personalization prior. This produces natural images that preserve personalized facial features as well as image degradation properties. Experiments demonstrate that this method can generate higher fidelity facial images compared to non-personalized methods.

Inpaint_wechat
Inpaint_wechat is a small program based on WeChat's AI capabilities. It realizes the function of eliminating and repairing selected areas of pictures. It is purely client-side and has no server. The product is positioned to provide a convenient picture repair solution without the need for additional server support.
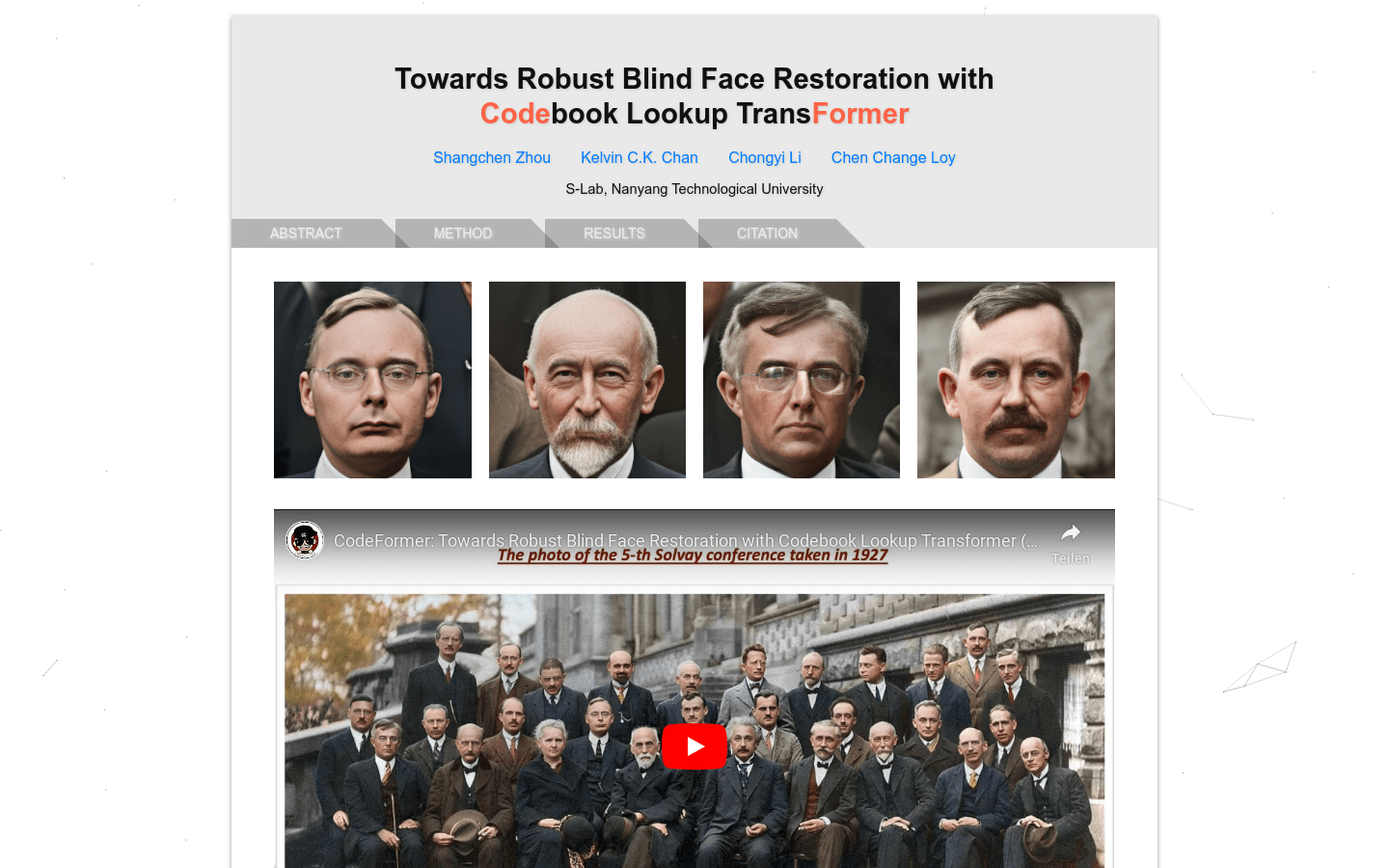
CodeFormer
CodeFormer is a Transformer-based prediction network for image mosaic restoration. By learning discrete codebooks and decoders, it is able to reduce the uncertainty of recovered mappings and generate high-quality faces. It has excellent anti-degradation robustness and is suitable for both synthetic and real data sets.

Lama Cleaner
Lama Cleaner is a free, open source AI image repair tool based on state-of-the-art AI models. It can remove any unwanted objects, blemishes or people from the picture, it can also erase and replace any object in the picture. The tool supports CPU, GPU, and M1/2, and offers a variety of SOTA AI models to choose from.

RealFill
RealFill is a generative model for image completion that uses a small number of reference images of the scene to fill in missing areas in the image and generate visual content consistent with the original scene. RealFill creates personalized generative models by fine-tuning pre-trained image completion diffusion models on reference and target images. The model not only maintains good image priors, but also learns the content, lighting, and style in the input images. We then use this fine-tuned model to fill in missing regions in the target image through a standard diffusion sampling process. RealFill was evaluated on a new image completion benchmark containing a variety of complex scenes and found to significantly outperform existing methods.
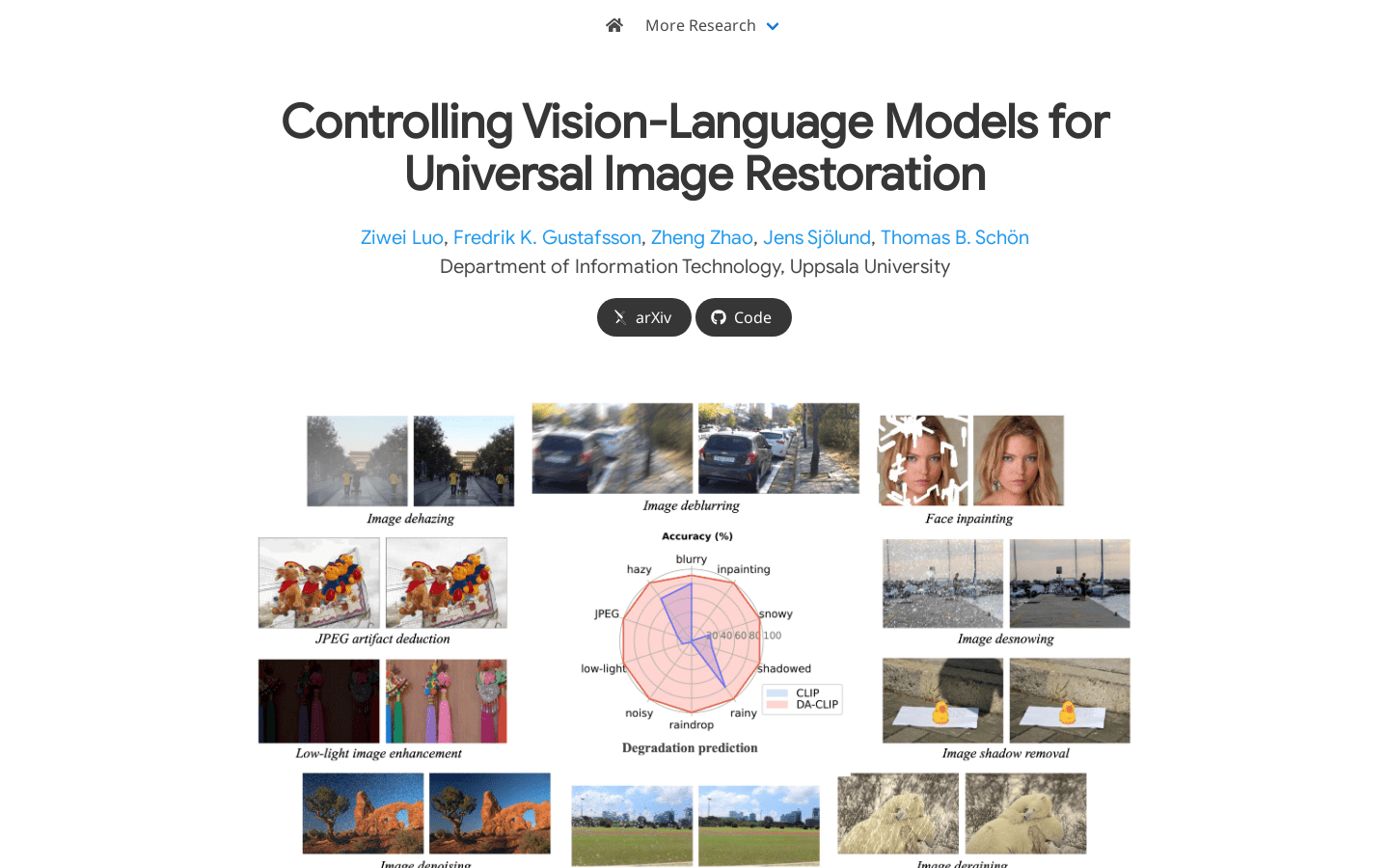
DA-CLIP
DA-CLIP is a degradation-aware visual language model that can be used as a general framework for image restoration. It learns high-fidelity image reconstruction by training an additional controller to enable a fixed CLIP image encoder to predict high-quality feature embeddings and integrating it into an image restoration network. The controller itself also outputs degradation signatures that match the true damage of the input, providing a natural classifier for different degradation types. DA-CLIP is also trained using a hybrid degraded dataset, improving the performance of specific degraded and unified image restoration tasks.

PGDiff
PGDiff is a versatile facial restoration framework suitable for a wide range of facial restoration tasks, including blind restoration, colorization, inpainting, reference-based restoration, old photo restoration, etc. It uses a guided diffusion model to achieve facial restoration through partial guidance. The advantage of PGDiff lies in its versatility and applicability, and can be applied to a variety of facial restoration tasks.

DiffBIR
DiffBIR is a blind image restoration model based on generative diffusion priors. It removes image degradation and refines image details through two stages of processing. The advantage of DiffBIR is that it provides high-quality image restoration results and has flexible parameter settings that can trade-off between fidelity and quality. Use of this model is free.
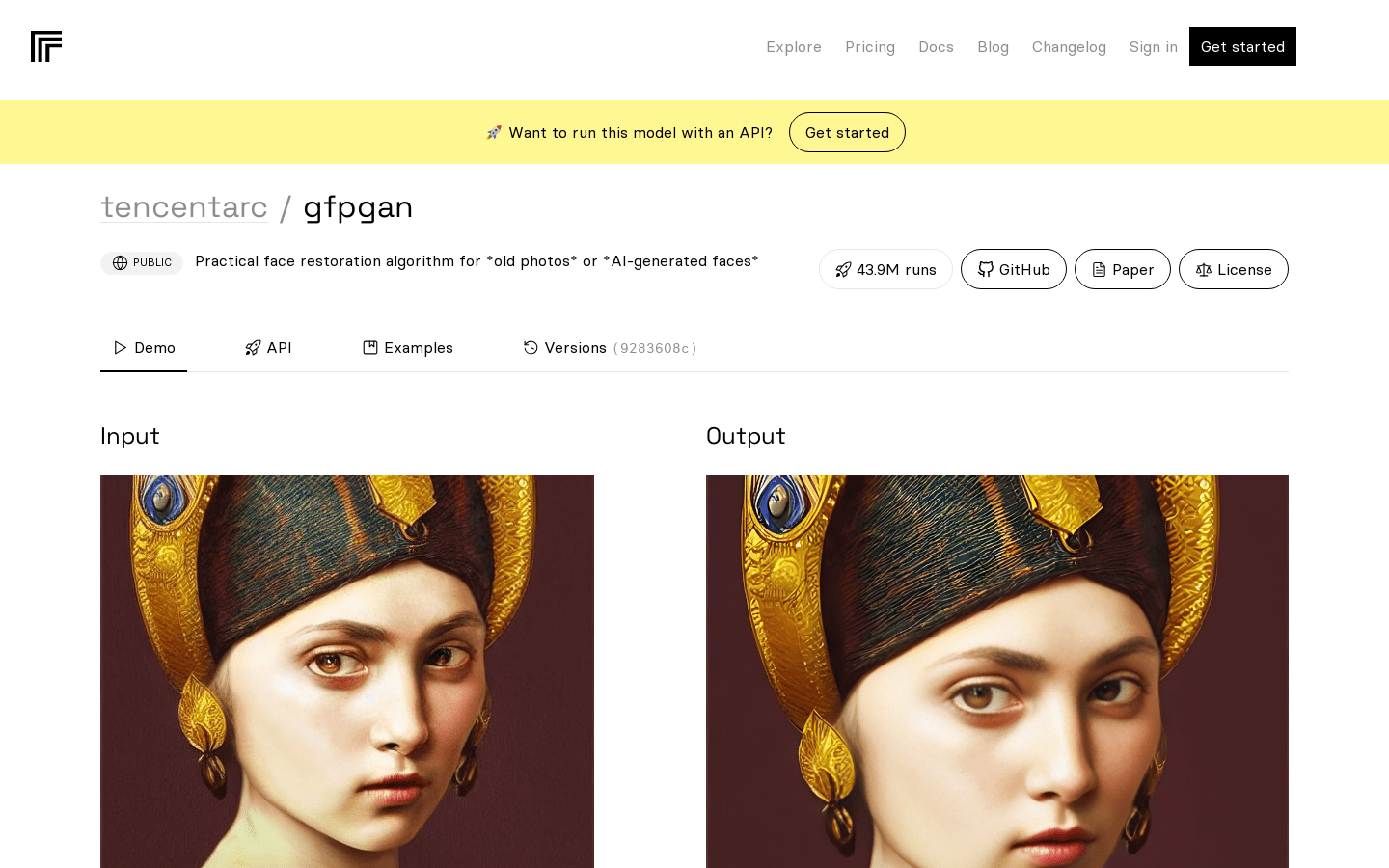
GFPGAN
GFPGAN is a practical facial restoration algorithm that can be used to repair old photos or generate faces. This algorithm has better quality and more details and can be used for identification. The model runs on Nvidia T4 GPU hardware, and predictions are typically completed in 17 seconds. If GFPGAN is helpful to you, please like the Github Repo and recommend it to your friends.