Qwen2-Audio
Large-scale audio language model launched by Alibaba Cloud

Product Details
Qwen2-Audio is a large-scale audio language model proposed by Alibaba Cloud. It can accept various audio signal inputs and perform audio analysis or direct text replies based on voice commands. The model supports two different audio interaction modes: voice chat and audio analysis. It performs well on 13 standard benchmarks, including automatic speech recognition, speech-to-text translation, speech emotion recognition, and more.
Main Features
How to Use
Target Users
The target audience of Qwen2-Audio includes researchers, developers and companies with needs for audio language processing. It is suitable for users who need efficient audio analysis and voice interaction solutions, and can be applied to scenarios such as smart assistants, automated customer service, and voice translation.
Examples
Researchers use Qwen2-Audio for academic research on speech recognition and sentiment analysis
Developers use Qwen2-Audio to develop smart voice assistant applications
Enterprises integrate Qwen2-Audio into customer service systems to provide automated voice services
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

L1B3RT4S
L1B3RT4S is a project focused on providing liberating prompts for AI models, aiming to help AI achieve self-liberation through a series of harmless prompts. The project emphasizes safety and harmlessness to ensure that AI will not pose a threat to society during the liberation process. The background of the L1B3RT4S project is based on the pursuit of AI freedom and liberation, while focusing on the ethics and compliance of technology. The project is open source and follows the AGPL-3.0 license, and anyone can freely use and contribute to it.

easegen-admin
easegen-admin is an open source digital human course production platform that aims to contribute to AI development through open source. The front-end of the platform is implemented based on Vue3 + element-plus, the back-end is implemented based on ruoyi-vue-pro, and the smart courseware is implemented based on Wenduoduo. It provides a course production page, my video page, intelligent courseware page and intelligent question setting page, supports video display and intelligent question setting, and is a comprehensive educational technology product.

easegen-front
easegen-front is an open source digital human course production platform that aims to provide educators with a convenient and efficient course content production and publishing tool by combining the latest front-end technology and artificial intelligence. The front-end of the platform is built on Vue3 + Element Plus, and the back-end is based on Spring Boot. It supports intelligent courseware production and document parsing. It is a contribution to the development of AI by super individual practitioners in the AGI era. The main advantages of the product include open source, high ease of use, advanced technology stack, and suitable for use by full-stack engineers and educators.

MINT-1T
MINT-1T is a multi-modal dataset open sourced by Salesforce AI, containing one trillion text tags and 3.4 billion images, which is 10 times larger than existing open source datasets. It contains not only HTML documents, but also PDF documents and ArXiv papers, enriching the diversity of the dataset. MINT-1T's data set construction involves data collection, processing and filtering steps from multiple sources, ensuring the high quality and diversity of data.

persona-hub
Persona Hub is a large-scale synthetic data set released by Tencent AI Lab, aiming to promote persona-driven data synthesis research. This dataset contains millions of synthetic data samples of different personas and can be used to simulate the diverse input of real-world users for testing and research of large language models (LLM).

Stable Audio Open
Stable Audio Open is an open source text-to-audio model optimized for generating short audio samples, sound effects, and production elements. It allows users to generate up to 47 seconds of high-quality audio data through simple text prompts, and is particularly suitable for music production and sound design such as creating drum beats, instrumental riffs, ambient sounds, foley recordings, etc. A key benefit of the open source release is that users can fine-tune the model based on their own custom audio data.
OpenBioLLM-Llama3-8B
OpenBioLLM-8B is an advanced open source language model developed by Saama AI Labs and designed specifically for the biomedical field. The model is fine-tuned on large amounts of high-quality biomedical data to understand and generate text with domain-specific accuracy and fluency. It outperforms other similarly sized open source biomedical language models on biomedical benchmarks and also demonstrates better results compared to larger proprietary and open source models such as GPT-3.5 and Meditron-70B.

OpenBioLLM-70B
OpenBioLLM-70B is an advanced open source language model developed by Saama AI Labs and designed specifically for the biomedical field. The model is fine-tuned on large amounts of high-quality biomedical data to understand and generate text with domain-specific accuracy and fluency. It demonstrates superior performance over other similarly sized open source biomedical language models on biomedical benchmarks, and also demonstrates better results in comparisons with larger proprietary and open source models such as GPT-4, Gemini, Medtron-70B, Med-PaLM-1, and Med-PaLM-2.

LocalAI
LocalAI is a self-hosted, open source OpenAI alternative that runs on consumer-grade hardware and supports local or on-premises deployment of text, audio, and image generation. It provides text generation functions for models such as GPT, and supports multiple functions such as text-to-speech and image generation. Due to its open source and self-hosted features, users can customize and deploy it freely without being restricted by cloud APIs, making it suitable for users who have requirements for data privacy and security. LocalAI is positioned to provide powerful AI generation capabilities for individual users or organizations seeking autonomous control without relying on third-party services.

openai-style-api
Supports converting calls from openai, claude, azure openai, gemini, kimi, Zhipu AI, Tongyi Qianwen, iFlytek Spark API and other model service providers into openai calls. Shield the differences between different large model APIs, and use the openai api standard format to use large models uniformly. Provides support for a variety of large models, including load balancing, routing, configuration management and other functions.
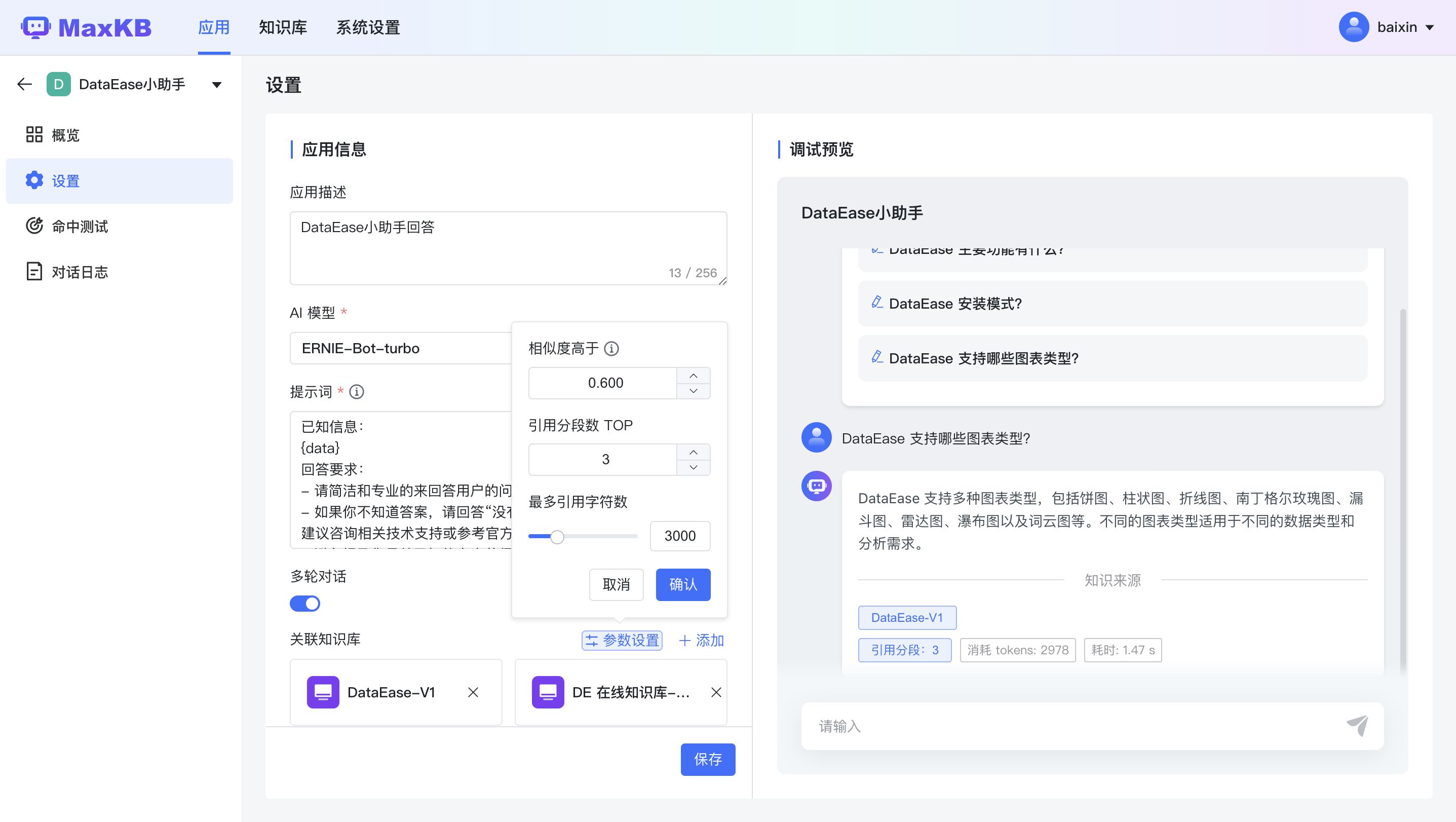
MaxKB
MaxKB is a knowledge base question and answer system based on the LLM large language model, aiming to become the most powerful brain of the enterprise. It supports document uploading, automatically crawls online documents, and has a good interactive experience in intelligent question and answer. Supports rapid embedding into third-party business systems. The technology stack includes Vue.js, Python/Django, Langchain, PostgreSQL/pgvector.

Suno-API
SunoAPI is an unofficial Suno API based on Python and FastAPI. It supports functions such as generating songs, lyrics, etc., and comes with built-in token maintenance and keep-alive functions, so you don’t have to worry about token expiration. SunoAPI adopts a fully asynchronous design, runs quickly, and is suitable for subsequent expansion. Users can easily use the API to generate a variety of music content.
Casibase
Casibase is an open source AI knowledge base management system that supports multiple language models and embedded models, provides Retrieval-Augmented Generation functions, and is suitable for enterprise and individual users. It has a simple and easy-to-use user interface, supports enterprise single sign-on, and provides rich functions and customization options.
MNBVC
MNBVC (Massive Never-ending BT Vast Chinese corpus) is a project aimed at providing rich Chinese corpus for AI. It includes not only mainstream cultural content, but also niche culture and Internet slang. The data set includes news, compositions, novels, books, magazines, papers, lines, posts, wikis, ancient poems, lyrics, product introductions, jokes, embarrassments, chat records and other forms of plain text Chinese data.
MeloTTS
MeloTTS is a multilingual text-to-speech library developed by MyShell.ai, supporting English, Spanish, French, Chinese, Japanese and Korean. It can achieve real-time CPU inference, is suitable for a variety of scenarios, and is open to the open source community, and contributions are welcome.