Llama3-s v0.2
The latest multi-modal checkpoints improve speech understanding capabilities.
Product Details
Llama3-s v0.2 is a multi-modal checkpoint developed by Homebrew Computer Company focused on improving speech understanding. The model is improved through early integration of semantic tags and community feedback to simplify the model structure, improve compression efficiency, and achieve consistent speech feature extraction. Llama3-s v0.2 performs stably on multiple speech understanding benchmarks and provides live demos, allowing users to experience its capabilities for themselves. Although the model is still in the early stages of development and has some limitations, such as being sensitive to audio compression and unable to handle audio longer than 10 seconds, the team plans to address these issues in future updates.
Main Features
How to Use
Target Users
Llama3-s v0.2 is suitable for researchers and developers in the fields of speech recognition and natural language processing. It can help them improve the accuracy of speech-to-text conversion, optimize multi-modal interaction systems, and provide support for speech model development for low-resource languages.
Examples
Researchers use Llama3-s v0.2 for speech recognition research to improve the processing efficiency of speech data sets.
Developers use this model to integrate into smart assistant applications to enhance voice interaction functions.
Educational institutions use Llama3-s v0.2 for pronunciation teaching assistance to enhance the language learning experience.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools
AgentSphere
AgentSphere is a cloud infrastructure designed specifically for AI agents, providing secure code execution and file processing to support various AI workflows. Its built-in functions include AI data analysis, generated data visualization, secure virtual desktop agent, etc., designed to support complex workflows, DevOps integration, and LLM assessment and fine-tuning.

Seed-Coder
Seed-Coder is a series of open source code large-scale language models launched by the ByteDance Seed team. It includes basic, instruction and inference models. It aims to autonomously manage code training data with minimal human investment, thereby significantly improving programming capabilities. This model has superior performance among similar open source models and is suitable for various coding tasks. It is positioned to promote the development of the open source LLM ecosystem and is suitable for research and industry.

Agent-as-a-Judge
Agent-as-a-Judge is a new automated evaluation system designed to improve work efficiency and quality through mutual evaluation of agent systems. The product significantly reduces evaluation time and costs while providing a continuous feedback signal that promotes self-improvement of the agent system. It is widely used in AI development tasks, especially in the field of code generation. The system has open source features, making it easy for developers to carry out secondary development and customization.

Search-R1
Search-R1 is a reinforcement learning framework designed to train language models (LLMs) capable of reasoning and invoking search engines. It is built on veRL and supports multiple reinforcement learning methods and different LLM architectures, making it efficient and scalable in tool-enhanced inference research and development.

automcp
automcp is an open source tool designed to simplify the process of converting various existing agent frameworks (such as CrewAI, LangGraph, etc.) into MCP servers. This makes it easier for developers to access these servers through standardized interfaces. The tool supports the deployment of multiple agent frameworks and is operated through an easy-to-use CLI interface. It is suitable for developers who need to quickly integrate and deploy AI agents. The price is free and suitable for individuals and teams.

PokemonGym
PokemonGym is a server-client architecture-based platform designed for AI agents to be evaluated and trained in the Pokemon Red game. It provides game state through FastAPI, supports human interaction with AI agents, and helps researchers and developers test and improve AI solutions.

Pruna
Pruna is a model optimization framework designed for developers. Through a series of compression algorithms, such as quantization, pruning and compilation technologies, it makes machine learning models faster, smaller and less computationally expensive during inference. The product is suitable for a variety of model types, including LLMs, visual converters, etc., and supports multiple platforms such as Linux, MacOS, and Windows. Pruna also provides the enterprise version Pruna Pro, which unlocks more advanced optimization features and priority support to help users improve efficiency in practical applications.

Bytedance Flux
Flux is a high-performance communication overlay library developed by ByteDance, designed for tensor and expert parallelism on GPUs. It supports multiple parallelization strategies through efficient kernels and compatibility with PyTorch, making it suitable for large-scale model training and inference. Key benefits of Flux include high performance, ease of integration, and support for multiple NVIDIA GPU architectures. It performs well in large-scale distributed training, especially in Mixture-of-Experts (MoE) models, significantly improving computational efficiency.

AoT
Atom of Thoughts (AoT) is a new reasoning framework that transforms the reasoning process into a Markov process by representing solutions as combinations of atomic problems. This framework significantly improves the performance of large language models on inference tasks through the decomposition and contraction mechanism, while reducing the waste of computing resources. AoT can not only be used as an independent inference method, but also as a plug-in for existing test-time extension methods, flexibly combining the advantages of different methods. The framework is open source and implemented in Python, making it suitable for researchers and developers to conduct experiments and applications in the fields of natural language processing and large language models.

3FS
3FS is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSD and RDMA networks to provide a shared storage layer to simplify distributed application development. Its core advantages lie in high performance, strong consistency and support for multiple workloads, which can significantly improve the efficiency of AI development and deployment. The system is suitable for large-scale AI projects, especially in the data preparation, training and inference phases.
DeepSeek-V3/R1 inference system
The DeepSeek-V3/R1 inference system is a high-performance inference architecture developed by the DeepSeek team to optimize the inference efficiency of large-scale sparse models. It uses cross-node expert parallelism (EP) technology to significantly improve GPU matrix computing efficiency and reduce latency. The system adopts a double-batch overlapping strategy and a multi-level load balancing mechanism to ensure efficient operation in a large-scale distributed environment. Its key benefits include high throughput, low latency, and optimized resource utilization for high-performance computing and AI inference scenarios.
Thunder Compute
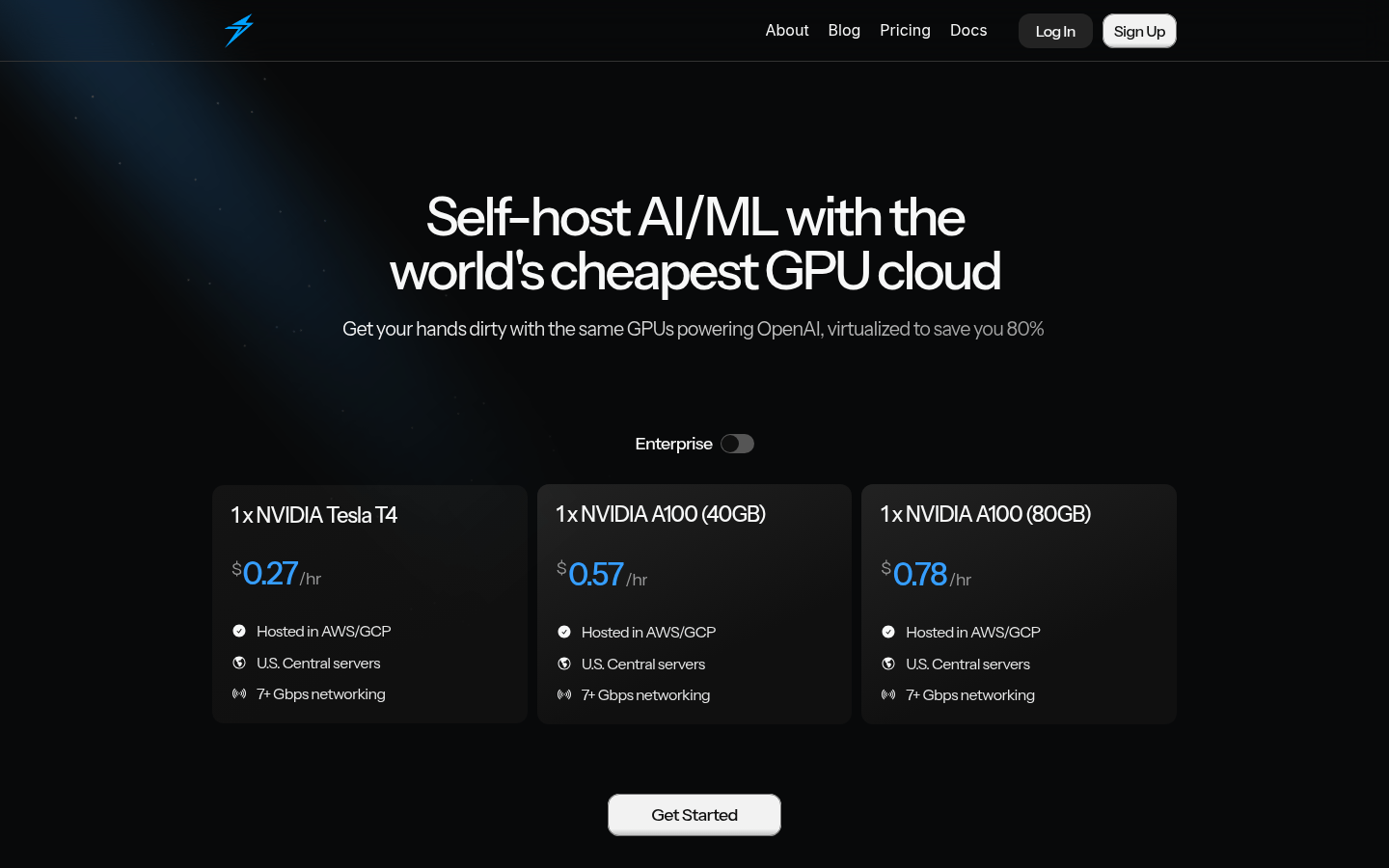
Thunder Compute is a GPU cloud service platform focused on AI/ML development. Through virtualization technology, it helps users use high-performance GPU resources at very low cost. Its main advantage is its low price, which can save up to 80% of costs compared with traditional cloud service providers. The platform supports a variety of mainstream GPU models, such as NVIDIA Tesla T4, A100, etc., and provides 7+ Gbps network connection to ensure efficient data transmission. The goal of Thunder Compute is to reduce hardware costs for AI developers and enterprises, accelerate model training and deployment, and promote the popularization and application of AI technology.
TensorPool
TensorPool is a cloud GPU platform focused on simplifying machine learning model training. It helps users easily describe tasks and automate GPU orchestration and execution by providing an intuitive command line interface (CLI). TensorPool's core technology includes intelligent Spot node recovery technology that can immediately resume jobs when a preemptible instance is interrupted, thus combining the cost advantages of preemptible instances with the reliability of on-demand instances. In addition, TensorPool selects the cheapest GPU options with real-time multi-cloud analysis, so users only pay for actual execution time without worrying about the additional cost of idle machines. The goal of TensorPool is to make machine learning projects faster and more efficient by eliminating the need for developers to spend a lot of time configuring cloud providers. It offers Personal and Enterprise plans, with the Personal plan offering $5 in free credits per week, while the Enterprise plan offers more advanced support and features.
MLGym
MLGym is an open source framework and benchmark developed by Meta's GenAI team and UCSB NLP team for training and evaluating AI research agents. It promotes the development of reinforcement learning algorithms by providing diverse AI research tasks and helping researchers train and evaluate models in real-world research scenarios. The framework supports a variety of tasks, including computer vision, natural language processing and reinforcement learning, and aims to provide a standardized testing platform for AI research.
DeepEP
DeepEP is a communication library designed for Hybrid Model of Experts (MoE) and Expert Parallel (EP). It provides high-throughput and low-latency fully connected GPU cores supporting low-precision operations (such as FP8). The library is optimized for asymmetric domain bandwidth forwarding and is suitable for training and inference pre-population tasks. In addition, it supports stream processor (SM) number control and introduces a hook-based communication-computation overlap method that does not occupy any SM resources. Although the implementation of DeepEP is slightly different from the DeepSeek-V3 paper, its optimized kernel and low-latency design make it perform well in large-scale distributed training and inference tasks.

FlexHeadFA
FlexHeadFA is an improved model based on FlashAttention that focuses on providing a fast and memory-efficient precise attention mechanism. It supports flexible head dimension configuration and can significantly improve the performance and efficiency of large language models. Key advantages of this model include efficient utilization of GPU resources, support for multiple head dimension configurations, and compatibility with FlashAttention-2 and FlashAttention-3. It is suitable for deep learning scenarios that require efficient computing and memory optimization, especially when processing long sequence data.