HelloMeme
Integrating spatial weaving attention to improve the high-fidelity conditions of diffusion models

Product Details
HelloMeme is a diffusion model integrating spatial weaving attention, aiming to embed high-fidelity and rich conditions into the image generation process. This technology generates videos by extracting the features of each frame in the driving video and using them as input to HMControlModule. By further optimizing the Animatediff module, the continuity and fidelity of the generated videos are improved. In addition, HelloMeme also supports facial expressions generated through ARKit facial blend shape control, as well as Lora or Checkpoint based on SD1.5, implementing a hot-swappable adapter for the framework that will not affect the generalization ability of the T2I model.
Main Features
How to Use
Target Users
HelloMeme's target audience is researchers and developers in the field of image generation, especially those users who have needs for high-fidelity and rich condition embeddings. This technology can help them generate more natural and continuous images and videos, while reducing sampling steps and improving efficiency.
Examples
Generate avatar videos with realistic facial expressions.
Create animated videos with high continuity and rich detail.
Generate high-quality motion graphics in game or film production.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

Hallo2
Hallo2 is a portrait image animation technology based on a latent diffusion generation model that generates high-resolution, long-term videos driven by audio. It expands Hallo's capabilities by introducing several design improvements, including generating long-duration videos, 4K resolution videos, and adding the ability to enhance expression control through text prompts. Hallo2's key advantages include high-resolution output, long-term stability, and enhanced control through text prompts, which make it a significant advantage in generating rich and diverse portrait animation content.

DreamMesh4D
DreamMesh4D is a new framework that combines mesh representation and sparsely controlled deformation technology to generate high-quality 4D objects from monocular videos. This technique solves the challenges of traditional methods in terms of spatial-temporal consistency and surface texture quality by incorporating implicit Neural Radiation Fields (NeRF) or explicit Gaussian rendering as the underlying representation. DreamMesh4D uses inspiration from modern 3D animation pipelines to bind Gaussian drawing to triangular mesh surfaces, enabling differentiable optimization of textures and mesh vertices. The framework starts from a coarse mesh provided by a single-image 3D generation method and constructs a deformation map by uniformly sampling sparse points to improve computational efficiency and provide additional constraints. Through two-stage learning, combined with reference view photometric loss, score distillation loss, and other regularization losses, the learning of static surface Gaussians and mesh vertices and dynamic deformation networks is achieved. DreamMesh4D outperforms previous video-to-4D generation methods in terms of rendering quality and spatial-temporal consistency, and its mesh-based representation is compatible with modern geometry pipelines, demonstrating its potential in the 3D gaming and film industries.

Inverse Painting
Inverse Painting is a diffusion model-based method that generates time-lapse videos of the painting process from a target painting. The technology learns the painting process of real artists through training, can handle multiple art styles, and generates videos similar to the painting process of human artists. It combines text and region understanding, defines a set of painting instructions, and updates the canvas using a novel diffusion-based renderer. This technique is not only capable of handling the limited acrylic painting styles in which it was trained, but also provides reasonable results for a wide range of art styles and genres.
DepthFlow
DepthFlow is a highly customizable parallax shader for animating your images. It is a free and open source ImmersityAI alternative capable of converting images into videos with 2.5D parallax effect. This tool has fast rendering capabilities and supports a variety of post-processing effects, such as vignette, depth of field, lens distortion, etc. It supports a variety of parameter adjustments, can create flexible motion effects, and has a variety of built-in preset animations. In addition, it also supports video encoding and export, including H264, HEVC, AV1 and other formats, and provides a user experience without watermarks.

Stable Video Portraits
Stable Video Portraits is an innovative hybrid 2D/3D generation method that utilizes pre-trained text-to-image models (2D) and 3D morphological models (3D) to generate realistic dynamic face videos. This technology upgrades the general 2D stable diffusion model to a video model through person-specific fine-tuning. By providing a time-series 3D morphological model as a condition and introducing a temporal denoising process, it generates a face image with temporal smoothness that can be edited and transformed into a text-defined celebrity image without additional test-time fine-tuning. This method outperforms existing monocular head avatar methods in both quantitative and qualitative analyses.

PhysGen
PhysGen is an innovative image-to-video generation method that converts single images and input conditions (e.g., forces and torques exerted on objects in the image) into realistic, physically plausible, and temporally coherent videos. The technology enables dynamic simulation in image space by combining model-based physical simulation with a data-driven video generation process. Key benefits of PhysGen include that the generated videos appear physically and visually realistic and can be precisely controlled, demonstrating its superiority over existing data-driven image-to-video generation efforts through quantitative comparisons and comprehensive user studies.
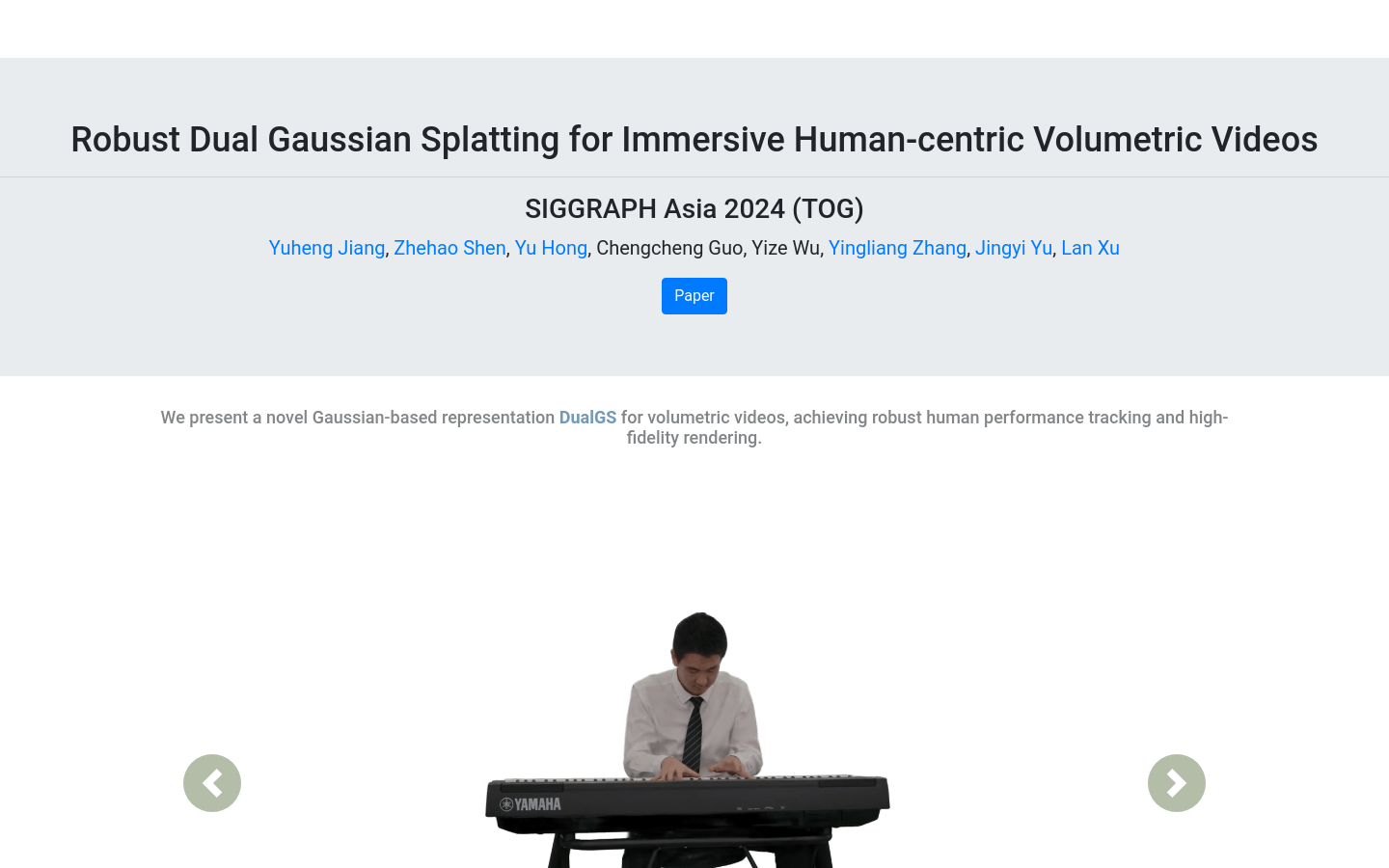
DualGS
Robust Dual Gaussian Splatting (DualGS) is a novel Gaussian-based volumetric video representation method that captures complex human performances by optimizing joint Gaussians and skin Gaussians and achieves robust tracking and high-fidelity rendering. Demonstrated at SIGGRAPH Asia 2024, the technology enables real-time rendering on low-end mobile devices and VR headsets, providing a user-friendly and interactive experience. DualGS achieves a compression ratio of up to 120 times through a hybrid compression strategy, making the storage and transmission of volumetric videos more efficient.

Generative Keyframe Interpolation with Forward-Backward Consistency
This product is an image-to-video diffusion model that can generate continuous video sequences with coherent motion from a pair of key frames through lightweight fine-tuning technology. This method is particularly suitable for scenarios where a smooth transition animation needs to be generated between two static images, such as animation production, video editing, etc. It leverages the power of large-scale image-to-video diffusion models by fine-tuning them to predict videos between two keyframes, achieving forward and backward consistency.

Animate3D
Animate3D is an innovative framework for generating animations for any static 3D model. Its core idea consists of two main parts: 1) Propose a new multi-view video diffusion model (MV-VDM), which is based on multi-view rendering of static 3D objects and trained on the large-scale multi-view video dataset (MV-Video) we provide. 2) Based on MV-VDM, a framework combining reconstruction and 4D Scored Distillation Sampling (4D-SDS) is introduced to generate animations for 3D objects using multi-view video diffusion priors. Animate3D enhances spatial and temporal consistency by designing a new spatiotemporal attention module and maintains the identity of static 3D models through multi-view rendering. In addition, Animate3D also proposes an efficient two-stage process to animate 3D models: first directly reconstructing motion from the generated multi-view video, and then refining the appearance and motion through the introduced 4D-SDS.

EchoMimic
EchoMimic is an advanced portrait image animation model capable of generating realistic portrait videos driven by audio and selected facial feature points individually or in combination. Through a novel training strategy, it solves the possible instability of traditional methods when driven by audio and the unnatural results that may be caused by facial key point driving. EchoMimic is comprehensively compared on multiple public and self-collected datasets and demonstrates superior performance in both quantitative and qualitative evaluations.

ControlNeXt
ControlNeXt is an open source image and video generation model that achieves faster convergence and superior efficiency by reducing trainable parameters by up to 90%. The project supports multiple forms of control information and can be combined with LoRA technology to change styles and ensure more stable generation effects.

VividDream
VividDream is an innovative technology that generates explorable 4D scenes with environmental dynamics from a single input image or text prompt. It first expands the input image into a static 3D point cloud, then uses a video diffusion model to generate an animated video collection, and achieves consistent motion and immersive scene exploration by optimizing the 4D scene representation. This technology makes it possible to generate engaging 4D experiences based on a variety of real-life images and text cues.

Follow-Your-Emoji
Follow-Your-Emoji is a portrait animation framework based on the diffusion model, which can animate the target expression sequence onto the reference portrait while maintaining the consistency of portrait identity, expression delivery, temporal coherence and fidelity. By employing expression-aware landmarks and facial fine-grained loss techniques, it significantly improves the model's performance in controlling free-style human expressions, including real people, cartoons, sculptures, and even animals. In addition, it extends to stable long-term animation through a simple and effective stepwise generation strategy, increasing its potential application value.

ToonCrafter
ToonCrafter is an open source research project focused on interpolating two cartoon images using pretrained image-to-video diffusion priors. The project aims to positively impact the field of AI-driven video generation, offering users the freedom to create videos but requiring users to comply with local laws and use responsibly.

Lumina-T2X
Lumina-T2X is an advanced text-to-arbitrary modality generation framework that converts text descriptions into vivid images, dynamic videos, detailed multi-view 3D images, and synthesized speech. The framework uses a flow-based large-scale diffusion transformer (Flag-DiT) that supports up to 700 million parameters and can extend sequence lengths to 128,000 markers. Lumina-T2X integrates images, videos, multi-views of 3D objects, and speech spectrograms into a spatiotemporal latent label space that can generate output at any resolution, aspect ratio, and duration.

StoryDiffusion
StoryDiffusion is an open source image and video generation model that can generate coherent long sequences of images and videos through a consistent self-attention mechanism and motion predictors. The main advantage of this model is that it is able to generate character-consistent images and can be extended to video generation, providing users with a new way to create long videos. The model has a positive impact on the field of AI-driven image and video generation, and users are encouraged to use the tool responsibly.