FunASR
Powerful voice offline file transcription service

Product Details
FunASR is a voice offline file transcription service software package that integrates voice endpoint detection, speech recognition, punctuation and other models. It can convert long audio and video into text with punctuation, and supports simultaneous transcription of multiple requests. It supports ITN and user-defined hot words, the server is integrated with ffmpeg, supports input of multiple audio and video formats, and provides multiple programming language clients. It is suitable for enterprises and developers who require efficient and accurate voice transcription services.
Main Features
How to Use
Target Users
The target audience is enterprise users who need to transcribe large amounts of voice data, developers, and research institutions with needs for speech recognition. FunASR's high accuracy and high concurrent processing capabilities are particularly suitable for scenarios that require processing large amounts of voice data, such as meeting record transcription, audio content production, voice data archiving, etc.
Examples
Enterprises use FunASR for real-time transcription of meeting recordings and quickly generate meeting minutes
The online education platform uses FunASR to convert lecture audio into text materials to facilitate student review
Media company uses FunASR to convert interview recordings into text to improve editing efficiency
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

AsrTools
AsrTools is a speech-to-text tool based on artificial intelligence technology. It implements efficient speech recognition functions without GPU and complex configuration by calling the ASR service interface of major manufacturers. This tool supports batch processing and multi-thread concurrency, and can quickly convert audio files into subtitle files in SRT or TXT format. The user interface of AsrTools is based on PyQt5 and qfluentwidgets, providing a high-looking and easy-to-operate interactive experience. Its main advantages include the stability of calling interfaces from major manufacturers, the convenience of not requiring complex configuration, and the flexibility of multi-format output. AsrTools is suitable for users who need to quickly convert speech content into text, especially in the fields of video production, audio editing and subtitle generation. Currently, AsrTools provides free use of ASR services from major manufacturers, which can significantly reduce costs and improve work efficiency for individuals and small teams.

NotesGPT
NotesGPT is an online service that uses artificial intelligence technology to convert users' voice notes into organized summaries and clear action items. It uses advanced speech recognition and natural language processing technology to help users record and manage notes more efficiently. It is especially suitable for users who need to quickly record information and organize it into structured content. Product background information shows that NotesGPT is technically supported by Together.ai and Convex, which shows that there is strong AI technology support behind it. At present, the product seems to be in the promotion stage, and the specific price and positioning information are not clearly displayed on the page.

Echo
Echo is a voice and text note-taking application that combines artificial intelligence technology. It uses AI technology to help users organize and refine their thinking. Utilizing the GPT-4o large-scale language model for transcription, recall, and insight generation, Echo is able to accurately transcribe the user's voice input and provide meaningful answers based on the user's past thoughts, making the diary experience more interactive and engaging. This product focuses on privacy and security, encrypts notes, does not view user data, does not use data to train AI, and follows industry best practices for data protection. Echo is currently in a free testing phase, with plans to introduce advanced features in the future.

gardener teleprompter
Gardener Teleprompter is a desktop teleprompter application specially designed for live broadcast, speech, teaching and other scenarios. It uses intelligent speech recognition technology to sense the user's speaking speed in real time, intelligently adjust the text scrolling speed, and ensure that word prompts and expressions are synchronized. The product integrates cutting-edge AI technology to provide copywriting optimization, omni-channel copywriting extraction, watermark-free video downloading, banned word detection, copywriting dubbing and other functions, significantly improving the efficiency of text creation. The Gardener teleprompter supports simultaneous playback of multiple windows to meet various display needs. All windows can be placed on top to avoid obstruction and achieve a truly invisible teleprompter. Product background information shows that the Gardener teleprompter has been tested in thousands of live broadcasts and is stable and durable. The team continues to innovate, iterate stably, and provide excellent services.

FineVoice
FineVoice is a multifunctional AI dubbing platform that uses advanced artificial intelligence technology to provide users with realistic and personalized voice services. This platform can not only convert text into natural and lifelike sounds, but also perform speech-to-text, voice-change and other operations, greatly enriching the possibilities of content creation. The main advantages of FineVoice include high efficiency, low cost, multi-language support and ease of use. It is especially suitable for individual and enterprise users who need to quickly generate large amounts of dubbing content.

Rev AI
Rev AI provides high-precision speech transcription services, supports more than 58 languages, and can convert speech to text in video and voice applications. It sets the accuracy standard for video and speech applications by training with the world's most diverse collection of sounds. Rev AI also provides services such as live streaming transcription, human transcription, language recognition, sentiment analysis, topic extraction, summarization and translation. Rev AI’s technical strengths include low word error rates, minimal bias against gender and racial accent, support for more languages, and the most readable transcripts possible. Additionally, it complies with the world's top security standards, including SOC II, HIPAA, GDPR, and PCI compliance.

Youtube-Whisper
Youtube-Whisper is a Gradio-based application that extracts the audio of YouTube videos and transcribes them into text using OpenAI’s Whisper model. This tool is useful for users who need to convert video content into text for analysis, archiving or translation. It leverages the latest artificial intelligence technology to improve the accessibility and usability of video content.

Whisper large-v3-turbo
Whisper large-v3-turbo is an advanced automatic speech recognition (ASR) and speech translation model proposed by OpenAI. It is trained on over 5 million hours of labeled data and is able to generalize to many datasets and domains in a zero-shot setting. This model is a fine-tuned version of Whisper large-v3, with the decoding layers reduced from 32 to 4 to increase speed, but may slightly reduce quality.

OmniSenseVoice
OmniSenseVoice is a speech recognition model optimized based on SenseVoice, designed for fast reasoning and precise timestamps, providing a smarter and faster audio transcription method.

CrisperWhisper
CrisperWhisper is an advanced variant of OpenAI-based Whisper model designed for fast, accurate, word-by-word speech recognition, providing accurate word-level timestamps. Compared to the original Whisper model, CrisperWhisper is designed to transcribe every spoken word word for word, including fillers, pauses, stutters and false starts. The model ranked first on verbatim datasets (e.g. TED, AMI) and was accepted at INTERSPEECH 2024.
babelfish.ai
babelfish.ai is a browser-based real-time speech-to-text and translation application. It utilizes Huggingface Transformer.js and Supabase Realtime technology to implement localized real-time speech recognition and multi-language translation functions. The application supports real-time conversion of speech into text and can translate text into 200 languages, greatly improving the efficiency and convenience of cross-language communication.

King of Han Dynasty Voice
Hanwang Voice King App is an intelligent voice flagship application independently developed by Hanwang Technology based on its self-developed multi-modal world model. It integrates AI voice recording, intelligent translation and simultaneous interpretation, and supports functions such as AI accurate transcription, recording synchronization, script organization, intelligent summary and uninterrupted real-time translation. Relying on full-stack AI technology, Hanwang Voice King is committed to helping users overcome language barriers and improve efficiency and convenience in office, study, conference, travel and other scenarios.
Real-time-translation-typing
Real-time-translation-typing is a software that integrates real-time typing translation, real-time voice typing and translation, and LOL voice typing functions. It is implemented through AutoHotkey technology and supports multiple translation APIs, such as Sogou, Baidu, Youdao, etc., providing users with an efficient and convenient translation experience. The software is suitable for business people, students and gamers who need to quickly translate text and speech.

CLASI
CLASI is a high-quality, human-like simultaneous interpretation system developed by ByteDance’s research team. It balances translation quality and latency with a novel data-driven reading and writing strategy, employs multi-modal retrieval modules to enhance translation of domain-specific terms, and leverages large language models (LLMs) to generate fault-tolerant translations that take into account input audio, historical context, and retrieval information. In real-world scenarios, CLASI achieved a valid information ratio (VIP) of 81.3% and 78.0% in the Chinese-English and English-Chinese translation directions respectively, far exceeding other systems.

aTrain
aTrain is an offline speech transcription tool developed by researchers at the Center for Business Analytics and Data Science at the University of Graz and tested by researchers at the Graz Knowledge Center. It leverages the latest machine learning models to automatically transcribe voice recordings without uploading any data. aTrain was introduced in a paper published in the Journal of Behavioral and Experimental Finance, please cite that paper if used for research. It supports Windows 10 and 11 systems, and users can download and install it through the Microsoft App Store or the BANDAS Center website. For Linux systems, an installation guide on the Wiki is provided. The main advantages of aTrain include privacy protection without the need to upload data, high-quality transcription quality, and fast processing speed on the local computer.
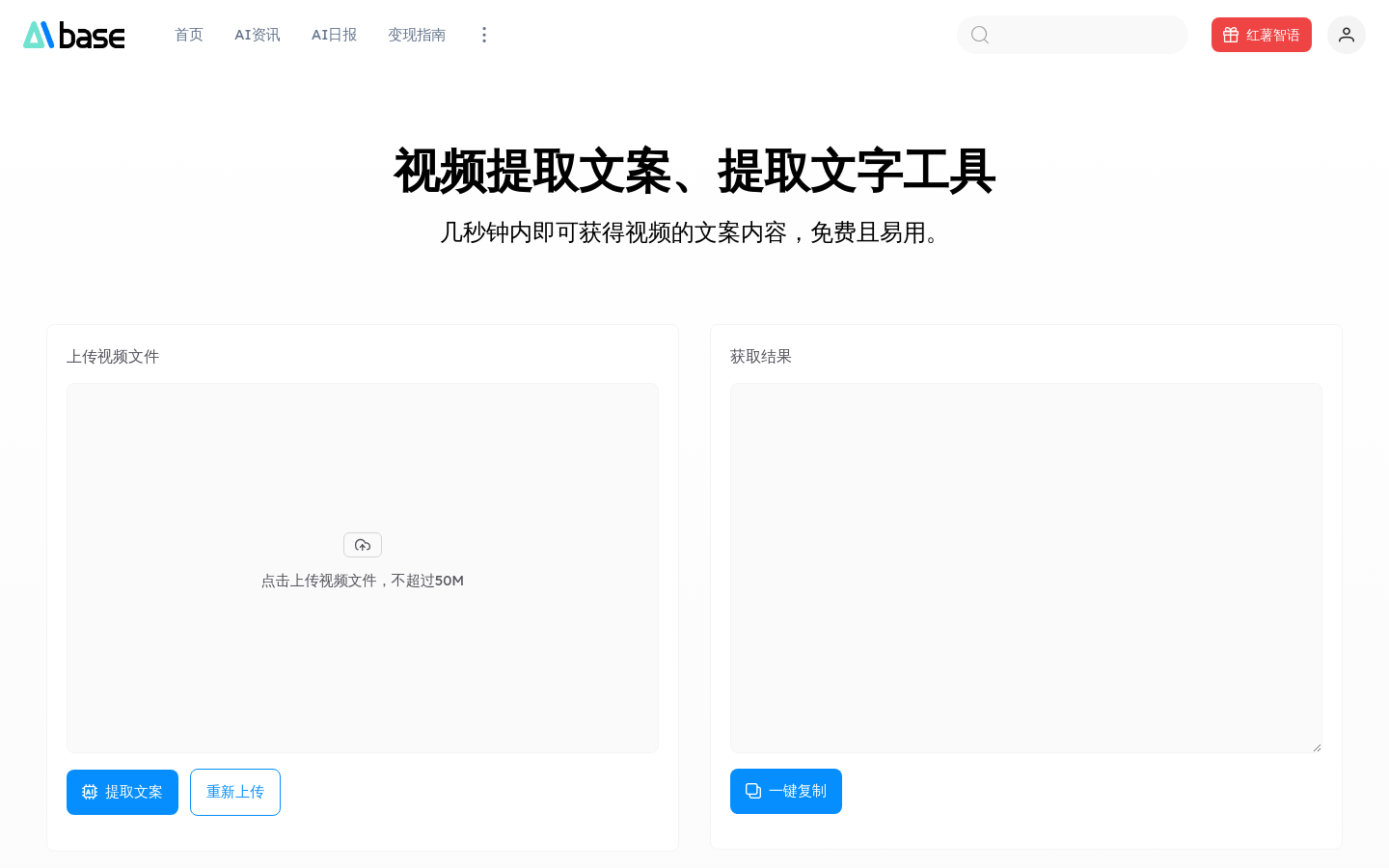
Video text extraction tool
AIbase video text extraction tool is a tool that uses artificial intelligence and machine learning technology to provide users with fast and accurate video text transcription services. It optimizes text layout, making the transcript easy to understand and faithful to the original video. As a basic service, this tool is completely free and requires no installation, download or paid subscription, greatly simplifying the video content processing work of creatives.