FaceFusion Labs
Industry-leading facial manipulation platform

Product Details
FaceFusion Labs is a leading platform focused on facial manipulation, leveraging advanced technology to enable the fusion and manipulation of facial features. The platform’s main advantages include high-precision facial recognition and fusion capabilities, as well as a developer-friendly API interface. FaceFusion Labs background information shows that it made an initial submission on October 15, 2024, and was developed by Henry Ruhs. The product is positioned as an open source project, encouraging community contributions and collaboration.
Main Features
How to Use
Target Users
FaceFusion Labs is suitable for developers, researchers, and enterprise users who are interested in facial recognition and operation technologies. It can help them implement face-related functions in various applications, such as facial recognition, expression cloning, virtual makeup try-on, etc.
Examples
Developers can use FaceFusion Labs to develop facial recognition applications, such as security authentication systems.
Researchers can use the platform to perform facial expression analysis to study human emotions.
Enterprises can integrate FaceFusion Labs’ API to provide personalized virtual makeup try-on services.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

photo4you
photo4you is an online ID photo production website based on artificial intelligence technology. Users can easily create ID photos without downloading or installing any software. The website supports a variety of standard sizes for official documents such as passports, visas, and driver's licenses. It automatically removes photo backgrounds through intelligent background removal, ensuring that ID photos have a clear, professional look. Users can download the produced ID photos immediately, saving time and trouble. photo4you provides high-resolution output suitable for printing or digital submission.

DreamWaltz-G
DreamWaltz-G is an innovative framework for text-driven generation of 3D avatars and expressive full-body animation. At its core is skeleton-guided scoring distillation and hybrid 3D Gaussian avatar representation. This framework improves the consistency of viewing angles and human poses by integrating the skeleton control of a 3D human template into a 2D diffusion model, thereby generating high-quality avatars and solving problems such as multiple faces, extra limbs, and blur. In addition, the hybrid 3D Gaussian avatar representation enables real-time rendering, stable SDS optimization and expressive animation by combining neural implicit fields and parametric 3D meshes. DreamWaltz-G is very effective in generating and animating 3D avatars, surpassing existing methods in both visual quality and animation expressiveness. Additionally, the framework supports a variety of applications, including human video reenactment and multi-subject scene composition.

HeadshotAI
HeadshotAI is a platform that uses artificial intelligence technology to generate realistic avatars. It uses advanced algorithms to analyze uploaded photos and generate avatars with professional photography effects. The importance of this technology is that it allows individuals to obtain high-quality avatars at a lower cost and in a more convenient way, thereby enhancing their personal brand and professional image. Key benefits of HeadshotAI include unparalleled realism, easy customization, rapid generation, affordability, and seamless integration.

MagicFace
MagicFace is a technology that enables personalized portrait synthesis without training and is able to generate high-fidelity portrait images based on multiple given concepts. This technology enables multi-concept personalization by precisely integrating reference concept features into generated regions at the pixel level. MagicFace introduces a coarse-to-fine generation process, including two stages of semantic layout construction and conceptual feature injection, implemented through the Reference-aware Self-Attention (RSA) and Region-grouped Blend Attention (RBA) mechanisms. Not only does this technology excel in portrait synthesis and multi-concept portrait customization, it can also be used for texture transfer, enhancing its versatility and practicality.
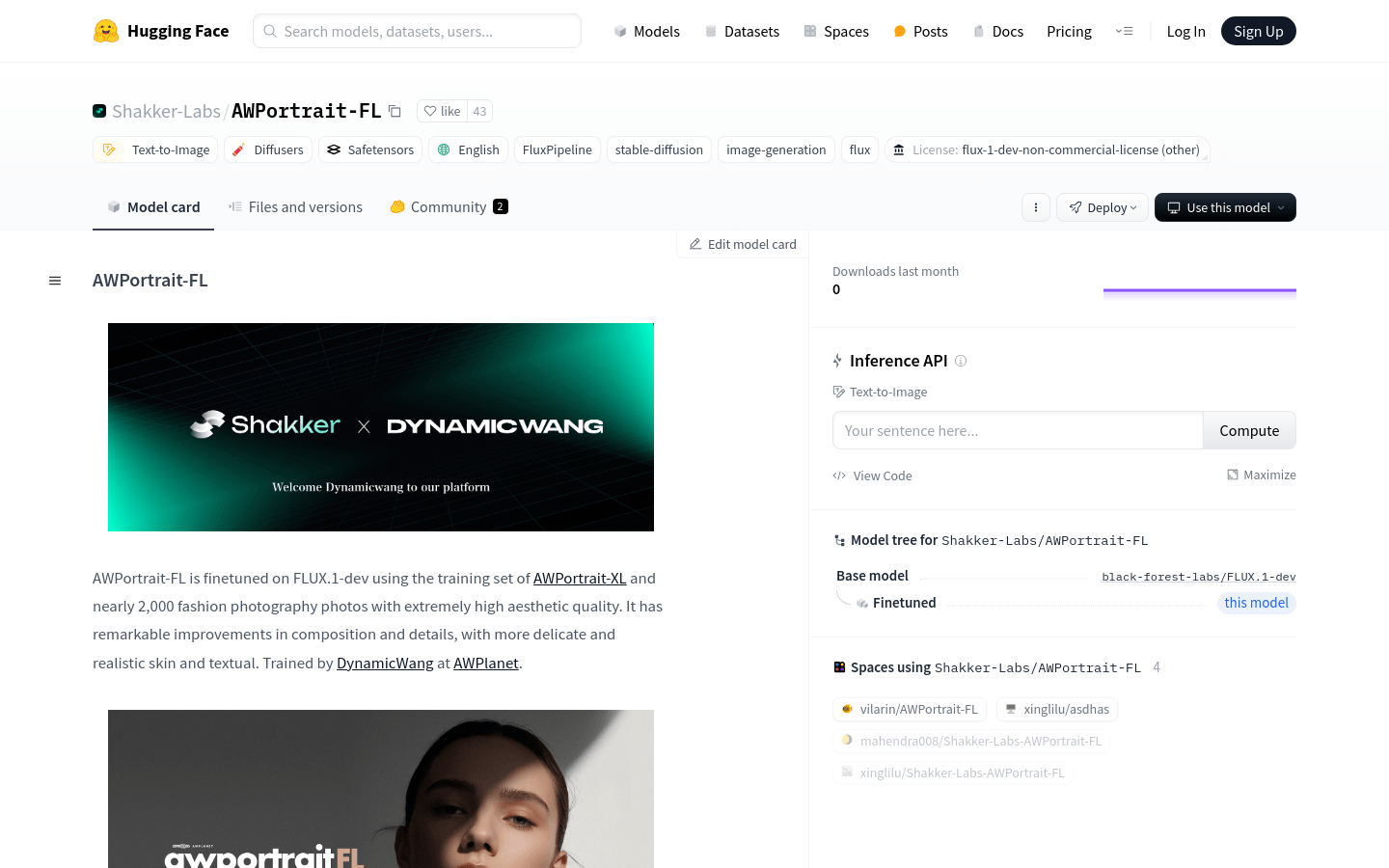
AWPortrait-FL
AWPortrait-FL is an advanced portrait generation model fine-tuned on the basis of FLUX.1-dev. It is trained using the AWPortrait-XL training set and nearly 2000 high-quality fashion photography photos. The model offers significant improvements in composition and detail, producing portraits with more detailed, realistic skin and textures. It is trained by DynamicWang on AWPlanet.

HivisionIDPhotos
HivisionIDPhotos is a lightweight AI ID photo production tool that uses advanced image processing algorithms to intelligently identify and cut out images to generate ID photos that meet a variety of specifications. The development background of this tool is to quickly respond to users' needs for ID photos on different occasions, and to improve the efficiency and quality of ID photo production through automated image processing technology. The main advantages of the product include lightweight, high efficiency, ease of use and support for multiple ID photo formats.
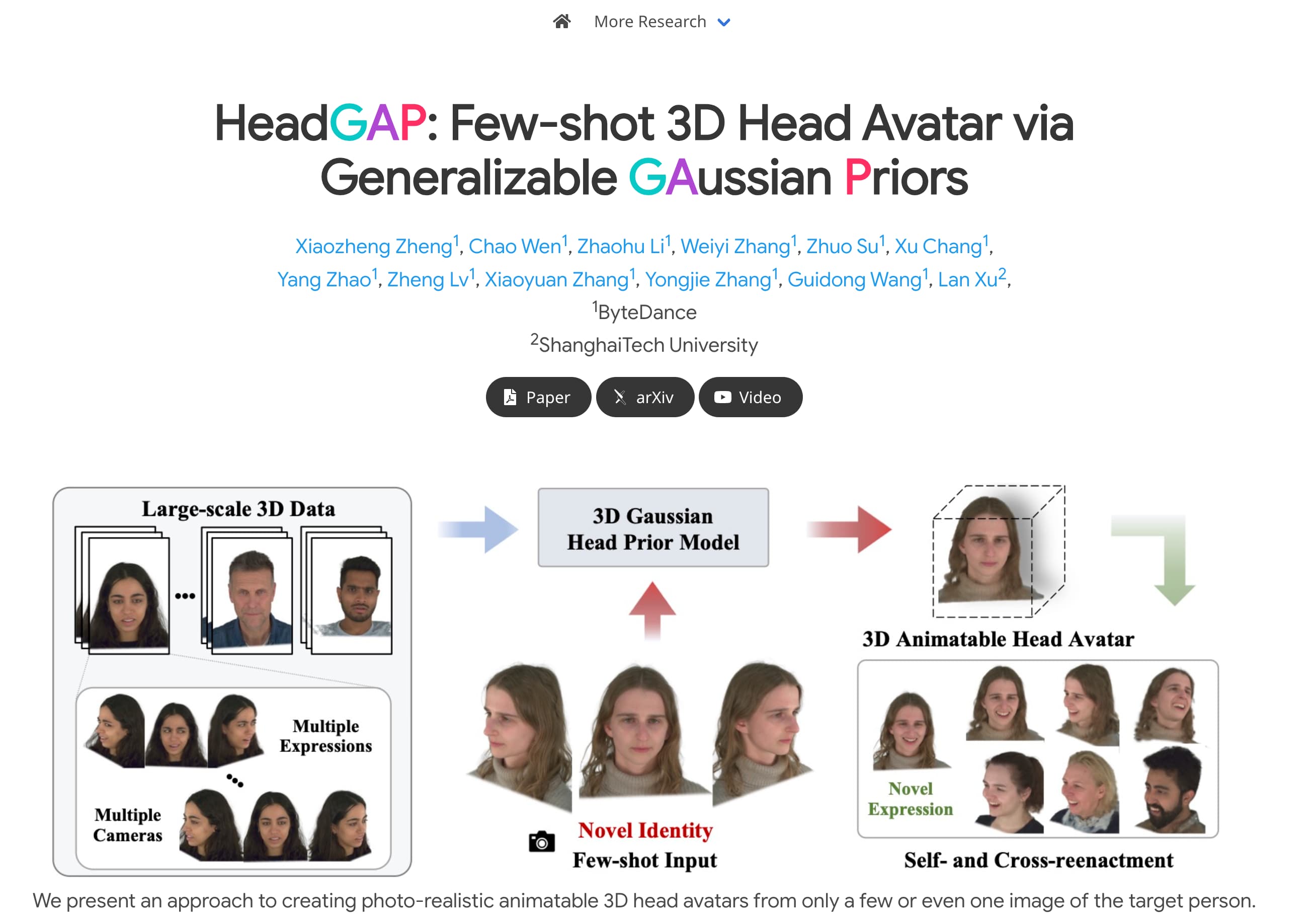
HeadGAP
HeadGAP is an advanced 3D avatar creation model that can create realistic and animatable 3D avatars from a small number or even a single picture of a target person. The model learns 3D head prior knowledge by utilizing large-scale multi-view dynamic data sets, and implements dynamic modeling through a self-decoding network based on Gaussian Splatting. HeadGAP learns the properties of Gaussian primitives through identity sharing encoding and personalized latent codes, achieving rapid avatar personalization.
UniPortrait
UniPortrait is an innovative portrait personalization framework that enables high-fidelity single-ID and multi-ID portrait customization through two plug-in modules: ID embedding module and ID routing module. The model extracts editable facial features through a decoupling strategy and embeds them into the context space of the diffusion model. The ID routing module adaptively combines and distributes these embedded features to corresponding areas in the synthetic image to achieve single-ID and multi-ID customization. UniPortrait achieves excellent performance in single-ID and multi-ID customization through a carefully designed two-stage training scheme.

XHand
XHand is a model developed by Zhejiang University that generates high-detail expressive gesture avatars in real time. It is created from multi-view videos and uses MANO pose parameters to generate high-detail meshes and renderings, achieving real-time rendering in different poses. XHand has significant advantages in image realism and rendering quality, especially in the fields of extended reality and games, and can instantly render realistic hand images.

Stable-Hair
Stable-Hair is a novel diffusion model-based hairstyle transfer method that can robustly transfer real-world diverse hairstyles to user-provided facial images for virtual try-on. The method excels when dealing with complex and diverse hairstyles, maintaining original identity content and structure while achieving highly detailed and high-fidelity transfer effects.

AIAvatarKit
AIAvatarKit is a tool for quickly building AI-based conversational avatars. It supports running on VRChat, Clusters, and other Metaverse platforms, as well as real-world devices. The tool is easy to start, has unlimited expansion capabilities, and can be customized to the user's needs. The main advantages include: 1. Multi-platform support: Can run on multiple platforms, including VRChat, Cluster and Metaverse platforms. 2. Easy to start: Users can start conversations immediately without complicated setup. 3. Scalability: Users can add unlimited functions as needed. 4. Technical support: VOICEVOX API, Google or Azure voice service API key and OpenAI API key are required.
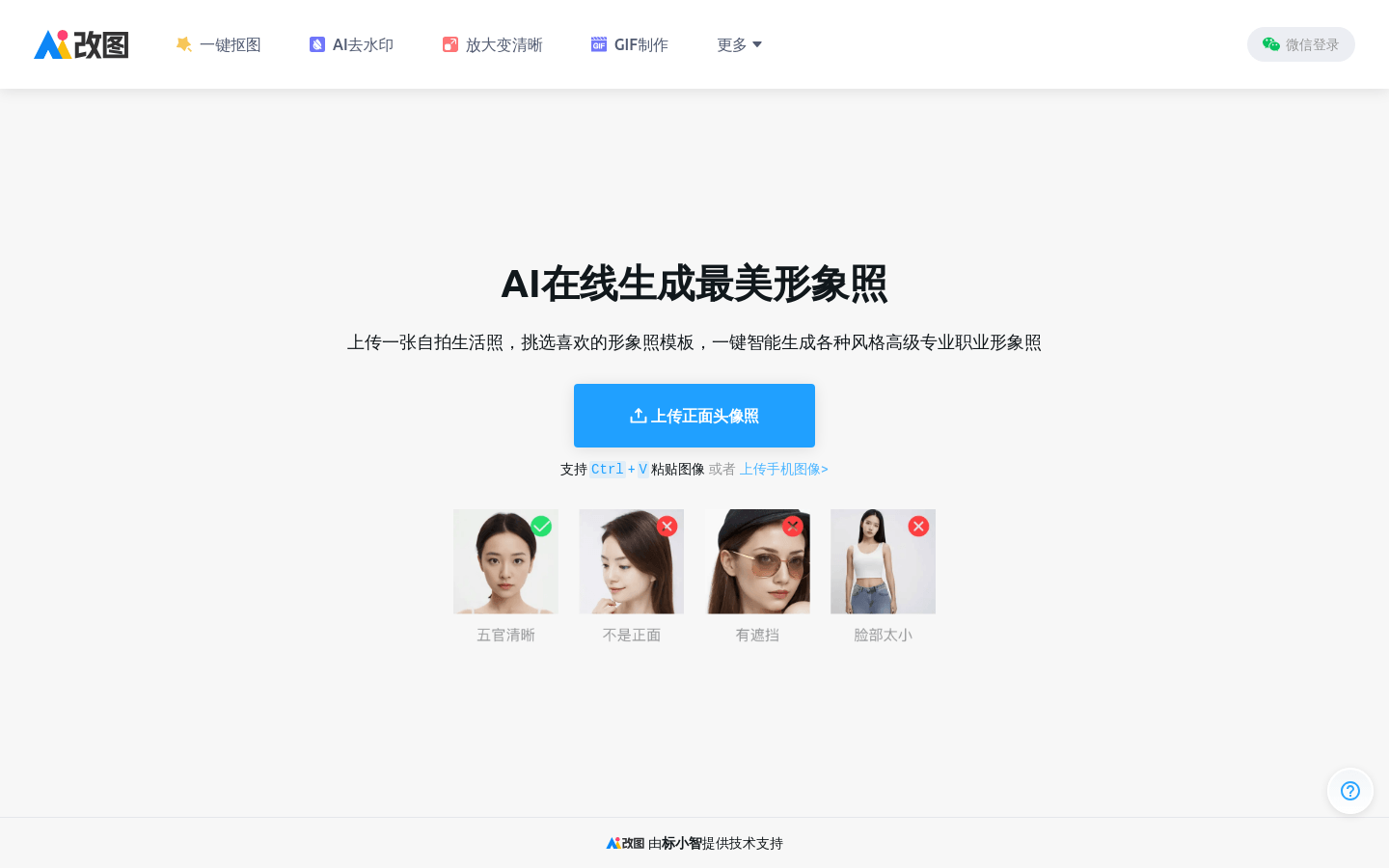
AI generates the most beautiful image photos online
AI online generation of the most beautiful image photos is an online service that uses artificial intelligence technology to quickly replace partial photos and generate professional artistic portrait photos with professional photo studio effects by users uploading frontal headshots. It combines advanced image processing technology with a user-friendly interface to provide users with a convenient and efficient way to improve and enhance the quality of personal image photos.

RodinHD
RodinHD is a high-fidelity 3D avatar generation technology based on the diffusion model. It was developed by researchers such as Bowen Zhang and Yiji Cheng. It aims to generate detailed 3D avatars from a single portrait image. This technology solves the shortcomings of existing methods in capturing complex details such as hairstyles. It integrates regularization terms through novel data scheduling strategies and weights to improve the decoder's ability to render sharp details. In addition, through multi-scale feature representation and cross-attention mechanism, the guidance effect of portrait images is optimized. The generated 3D avatar is significantly better in details than previous methods and can be generalized to wild portrait input.

Hallo
Hallo is a portrait image animation technology developed by Fudan University that uses diffusion models to generate realistic and dynamic portrait animations. Unlike traditional intermediate facial representations that rely on parametric models, Hallo adopts an end-to-end diffusion paradigm and introduces a layered audio-driven visual synthesis module to enhance the alignment accuracy between audio input and visual output, including lips, expressions, and gesture movements. This technology provides adaptive control of the diversity of expressions and postures, can more effectively achieve personalized customization, and is suitable for people with different identities.

E3Gen
E3Gen is a new digital avatar generation method that can generate high-fidelity avatars in real time, with detailed clothing folds, and supports multiple viewing angles and comprehensive control of full-body poses, as well as attribute transfer and local editing. It solves the problem of 3D Gaussian incompatibility with current generation pipelines by encoding 3D Gaussian into a structured 2D UV space, and explores the expressive animation of 3D Gaussian in training involving multiple subjects.

ID-to-3D
ID-to-3D is an innovative approach that enables the generation of identity- and text-guided 3D human head models with separated expressions from a randomly captured wild image. The method is based on compositionality and uses a task-specific 2D diffusion model as a prior for optimization. By extending the base model and adding lightweight expression-aware and identity-aware architectures, a 2D prior is created for geometry and texture generation, and by fine-tuning only 0.2% of the available training parameters. Combining powerful facial identity embeddings and neural representations, this method is able to accurately reconstruct not only facial features, but also accessories and hair, and can provide render-ready assets suitable for gaming and telepresence.