LongVU
Spatiotemporal adaptive compression model for long video language understanding

Product Details
LongVU is an innovative long video language understanding model that reduces the number of video tags through a spatiotemporal adaptive compression mechanism while retaining visual details in long videos. The importance of this technology lies in its ability to process a large number of video frames with only a small loss of visual information within the limited context length, significantly improving the ability to understand and analyze long video content. LongVU outperforms existing methods on multiple video understanding benchmarks, especially on the task of understanding hour-long videos. Additionally, LongVU is able to efficiently scale to smaller model sizes while maintaining state-of-the-art video understanding performance.
Main Features
How to Use
Target Users
LongVU's target audience is researchers and developers in the field of video content analysis and understanding, especially professionals who need to process long video content and want to achieve efficient video understanding under limited computing resources. In addition, LongVU provides an advanced solution for enterprises and institutions that want to apply the latest artificial intelligence technology in the field of video analysis.
Examples
When users ask for video content details, LongVU can provide detailed video scene descriptions.
Users ask questions about specific actions in the video, and LongVU can accurately identify and answer them.
Users need to know the moving direction of specific objects in the video, and LongVU can accurately identify and describe object movement.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools
Wan 2.2 Animate
Wan2.2 Animate is a free online advanced AI character animation tool. It is developed based on cutting-edge research and rigorous academic research results of Alibaba Tongyi Laboratory. It uses open source technology and model weights are available on the Hugging Face and ModelScope platforms. Its main advantage is that it provides precise facial expression control, body movement copying, seamless character replacement and other functions. It can create character animations while maintaining the original movements, environmental background and lighting conditions. It does not require registration and can be run directly in the browser. It is suitable for academic research, effect display and creative experiments.

CameraBench
CameraBench is a model for analyzing camera motion in video, aiming to understand camera motion patterns through video. Its main advantage lies in utilizing generative visual language models for principle classification of camera motion and video text retrieval. By comparing with traditional structure-from-motion (SfM) and real-time localization and construction (SLAM) methods, the model shows significant advantages in capturing scene semantics. The model is open source and suitable for use by researchers and developers, and more improved versions will be released in the future.

Movie Gen Bench
Movie Gen Bench is a video generation evaluation benchmark published by Facebook Research, aiming to provide a fair and easily comparable standard for future research in the field of video generation. The benchmark test includes two parts, Movie Gen Video Bench and Movie Gen Audio Bench, which evaluate video content generation and audio generation respectively. The release of Movie Gen Bench is of great significance to promote the development and evaluation of video generation technology. It can help researchers and developers better understand and improve the performance of video generation models.

DenseAV
DenseAV is a novel dual-encoder localization architecture that learns high-resolution, semantically meaningful audio-visual alignment features by watching videos. It is able to discover the "meaning" of words and the "place" of sounds without explicit localization supervision, and automatically discovers and differentiates between these two types of associations. DenseAV’s localization capabilities come from a new multi-head feature aggregation operator that directly compares dense image and audio representations for comparative learning. Furthermore, DenseAV significantly surpasses the previous state-of-the-art on semantic segmentation tasks and outperforms ImageBind on cross-modal retrieval using less than half the parameters.
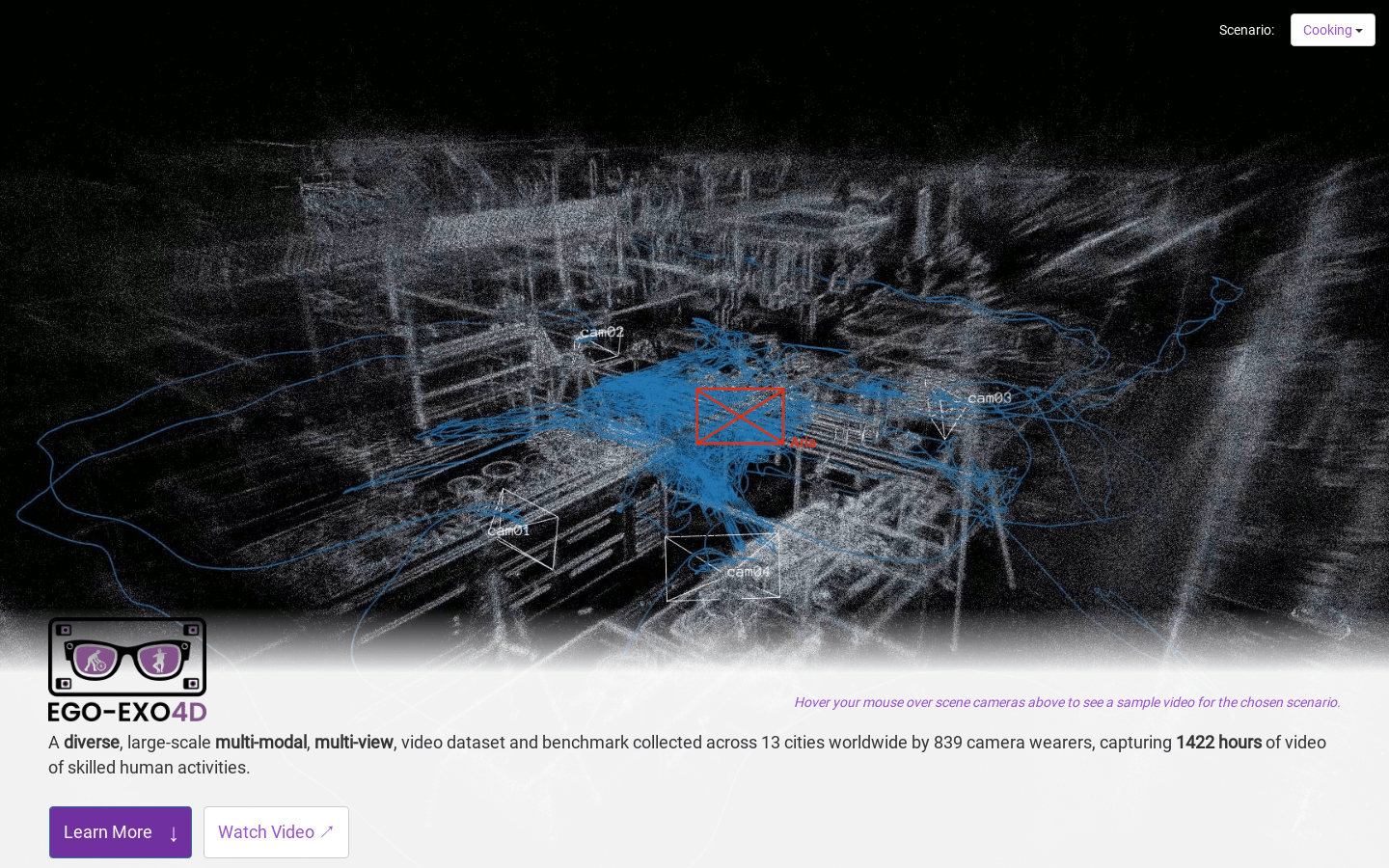
Ego-Exo4D
Ego-Exo4D is a multi-modal multi-view video dataset and benchmark challenge centered on capturing egocentric and exocentric videos of skilled human activities. It supports multimodal machine perception research in daily life activities. The dataset was collected by 839 camera-wearing volunteers in 13 cities around the world, capturing 1,422 hours of video of skilled human activity. This dataset provides three natural language datasets such as expert comments, tutorial-style narratives provided by participants, and atomic action descriptions in one sentence, paired with videos. Ego-Exo4D also captures multiple viewpoints and multiple perception modalities, including multiple viewpoints, seven microphone arrays, two IMUs, a barometer, and a magnetometer. Datasets were recorded in strict compliance with privacy and ethics policies and with formal consent from participants. For more information, please visit the official website.

Wan 2.5 AI
Wan 2.5 AI is a professional video generator using revolutionary wan 2.5 audio synchronization technology. Its importance lies in enabling efficient and high-quality video creation. Key benefits include: the ability to generate HD video up to 1080p resolution, audio and video perfectly synchronized without the need for manual adjustments, excellent multi-language processing capabilities, and the ability to generate videos up to 10 seconds long. In terms of price, there are different packages to choose from such as basic package, professional package and enterprise package, which are cost-effective. This product is positioned to meet the video production needs of global users in social media marketing, professional content creation, etc.

WAN 2.5 AI Video Generator
WAN 2.5 is a cutting-edge AI video generation platform that converts text prompts and images into professional-quality videos. Designed for content creators, marketers, and businesses, the platform is important to make video creation more efficient and convenient. Key advantages include lightning-fast generation speeds, support for multiple video formats, enterprise-level APIs, and more. The platform uses advanced AI models for real-time processing, which can meet the needs of video production in different scenarios. In terms of price, although the specific charging standards are not mentioned, there are related statements starting from US$99, which is speculated to be a payment model. Its positioning is to provide professional video generation solutions for all types of users and promote the development of the field of video creation.

SlideStorm
SlideStorm.ai is an AI slide generation and scheduling tool specially designed for TikTok. Its importance lies in helping users quickly create and publish TikTok slideshows, saving time and energy. The main advantages include the ability to easily create slideshows with a powerful AI generator, a full-featured slideshow editor, a rich image library, and support for batch generation of slideshows. The product background is to meet the needs of TikTok users for efficient content creation. In terms of price, there is a free trial, and then there are different levels of paid packages, including a $19 monthly entry package, a $49 professional package, and a $99 advanced package. It is positioned for TikTok content creators with different needs and can be used by beginners to professional users.

Talking Photo
AI Talking Photo Generator is a tool that uses artificial intelligence technology to convert still photos into talking animations. Its importance lies in providing innovative content presentation methods for various industries and creative projects. Key benefits include the generated animated lip sync and natural facial expressions, support for professional photos and ordinary snapshots, and the ability to generate audio via text-to-speech functionality for a variety of audio file formats. In terms of product background, it is designed to meet the needs of different industries for interactive content, such as virtual events, online education, museums, and tourism. In terms of price, trial points are provided and it is a free trial model. Positioned to help users easily create interactive and engaging content.

AI ASMR Generator
AI ASMR Generator is a website-based video generation tool that uses advanced AI technology to create templates in various popular formats by analyzing millions of viral ASMR videos. Its importance lies in providing content creators and marketers with a convenient way to create videos. The main advantages include no need to write prompt words, quick customization, multiple template choices, generation of synchronized audio and visual content, adaptation to social media algorithms, etc. The product background is developed for the needs of ASMR content creation. In terms of price, there are different subscription plans, including the $9.9 monthly Starter package, the $19.9 Creator package, and the $49 Pro package, which are positioned to meet the needs of content creators at different levels.
HiClip
HiClip is a product focused on video processing. Its core technology is to use AI to convert long videos into short videos. The importance lies in meeting the current massive demand for short video content on social media and helping users efficiently produce videos suitable for dissemination on social platforms. The main advantages include automating operations, saving time on editing and editing; and being able to quickly generate short videos with high conversion rates. The product background may be to adapt to the popular trend of short videos and meet the needs of creators and marketers. No price information is mentioned, but it is positioned as a productivity tool for video processing.

Wan 2.5
Wan 2.5 is a revolutionary native multi-modal video generation platform that represents a major breakthrough in video AI. It has a native multi-modal architecture that supports unified text, image, video and audio generation. Key benefits include synchronized AV output, 1080p HD cinematic quality, and alignment with human preferences through advanced RLHF training. The platform is based on the open source Apache 2.0 license and is available to the research community. The current document does not mention price information. Its positioning is to provide professional video creation solutions to global creators to help them achieve better results in the field of video creation.

Kling 2.5
Kling 2.5 AI is an advanced video generation tool that uses cutting-edge AI technology to create professional videos at a lower cost and faster speed. Its advantage is that it has advanced physical simulation, character animation and movie-level effects, reducing costs by 30% and increasing processing speed by 50%. Ideal for content creators, marketers, filmmakers, and more to create marketing videos, promotional content, and commercial videos. In terms of price, it has a flexible pricing strategy, such as 30 cents for 5 seconds of premium video content and 50 cents for 10 seconds. It also provides free trials.

Footage
Footage is a website product focusing on AI video generation. Its core technology is to use artificial intelligence algorithms to generate high-quality video content based on images and text prompts provided by users. The importance of this product is that it provides users with an efficient and convenient way to create videos without the need for complex video production skills. The main advantages of the product include simple operation and the ability to quickly generate videos from images and text; saving time and reducing the tedious steps in the traditional video production process. In terms of price, although Pricing is mentioned on the page, the price information is not clear. It is speculated that there may be a free trial or a paid model. The product is positioned for the majority of users who have video creation needs. Whether they are individual creators, corporate promotion departments, or video studios, they can quickly achieve video creation with the help of this product.

Kling 2.5 AI
Kling2.5 Turbo is an AI video generation model that significantly improves the understanding of complex causal relationships and time series. It has the characteristics of cost-optimized generation. The cost of generating a 5-second high-quality video is reduced by 30% (25 points vs. 35 points), and the motion smoothness is excellent. It uses advanced reasoning intelligence to understand complex causal relationships and time instructions, greatly improving motion smoothness and camera stability while optimizing costs. It's also the world's first model to output native 10, 12 and 16-bit HDR video in EXR format, suitable for professional studio workflows and pipelines. Additionally, its draft mode generates 20 times faster, making it easy to iterate quickly. The product has a variety of price plans, including a free entry version, a $29 professional version, and a $99 studio version, suitable for users with different needs, from individual creators to corporate teams.