Amazon Nova Sonic
Amazon’s new basic model understands tone, intonation and rhythm to improve the naturalness of human-machine dialogue.

Product Details
Amazon Nova Sonic is a cutting-edge basic model that integrates speech understanding and generation to improve the natural fluency of human-machine dialogue. This model overcomes the complexity in traditional voice applications and achieves deeper communication understanding through a unified architecture. It is suitable for AI applications in multiple industries and has important business value. With the continuous development of artificial intelligence technology, Nova Sonic will provide customers with a better voice interaction experience and improve service efficiency.
Main Features
How to Use
Target Users
This product is particularly suitable for developers and enterprise customers, especially those teams that need to build natural language processing applications. Due to its high adaptability and smooth conversational capabilities, Nova Sonic can effectively improve the customer service experience.
Examples
Travel Assistant: An AI assistant provides personalized travel recommendations based on the customer’s inflection.
Enterprise Assistant: AI assistant leverages company data to generate natural business reports and interact with them.
Online education: AI teachers adjust teaching content based on students’ questions and emotions.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools
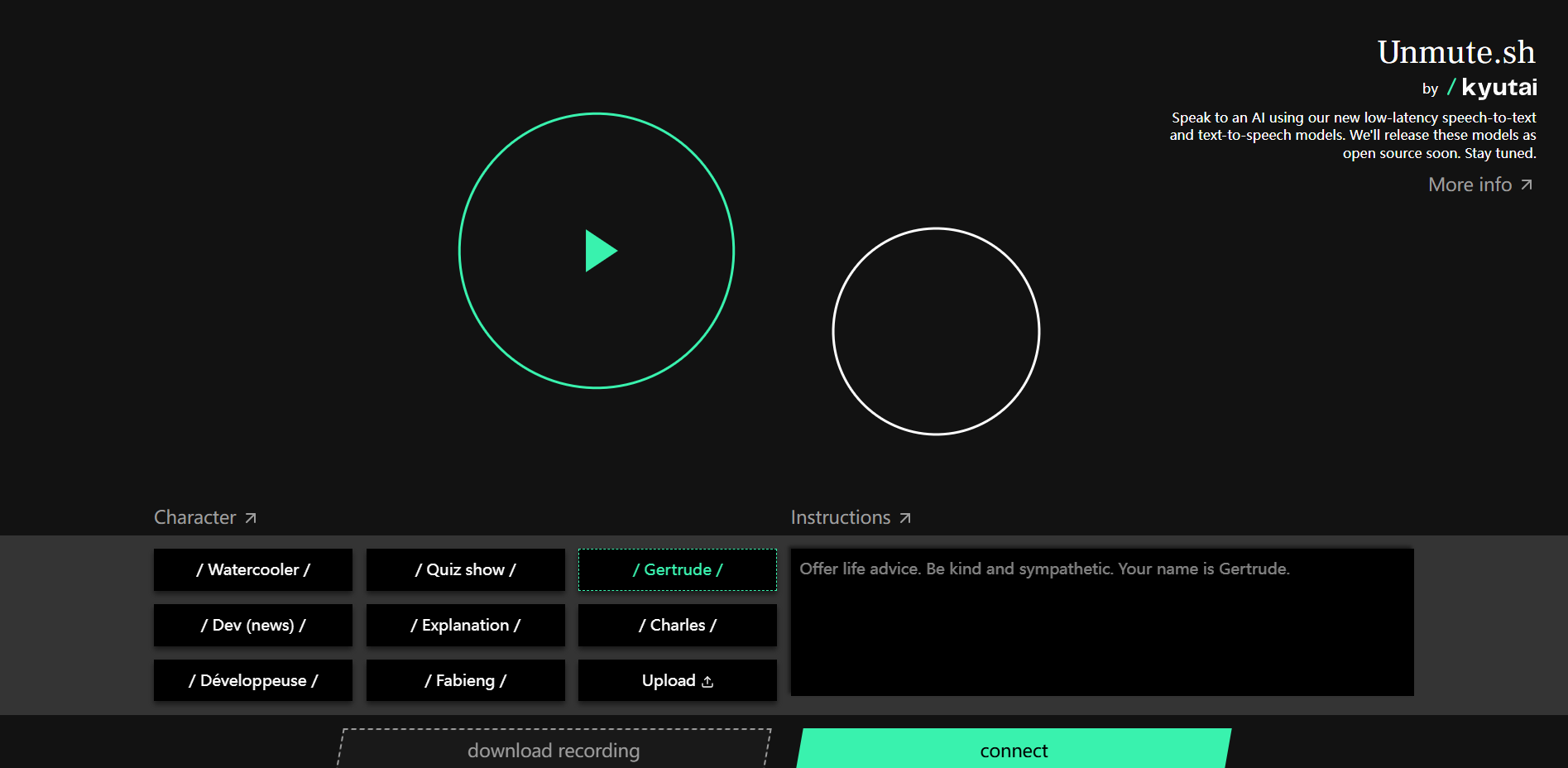
Unmute
Unmute is an innovative speech recognition and synthesis tool designed to enable users to efficiently interact with AI through natural language. Its low-latency technology ensures a smooth user experience and is suitable for scenarios that require real-time feedback. The product will be released as open source to promote the participation of more developers and users. The price has not yet been announced, but it is expected to be a combination of free and paid models.

Alexa+
Alexa+ is Amazon’s next-generation smart voice assistant to be launched in 2025, built on generative AI technology. It not only enables natural and smooth conversations, but also connects to thousands of services and devices to help users complete various tasks. Its core strengths are strong language understanding capabilities, personalized services, and seamless device integration. The launch of Alexa+ marks the transformation of voice assistants from a simple question and answer tool to a true smart life assistant that can help users better manage their daily lives and smart home devices.

Step-Audio
Step-Audio is the first production-level open source intelligent voice interaction framework that integrates speech understanding and generation capabilities, and supports multi-language dialogue, emotional intonation, dialect, speaking speed and rhythm style control. Its core technologies include 130B parameter multi-modal model, generative data engine, fine speech control and enhanced intelligence. This framework promotes the development of intelligent voice interaction technology through open source models and tools, and is suitable for a variety of voice application scenarios.

Bai Ling
Bailing is an open source voice conversation assistant designed to have natural conversations with users through voice. The project combines speech recognition (ASR), voice activity detection (VAD), large language model (LLM) and speech synthesis (TTS) technologies to provide a high-quality voice conversation experience. Its main advantage is that it can achieve GPT-4o-like dialogue effects without a GPU, and is suitable for various edge devices and low-resource environments. Bailing is completely open source and encourages community contributions and secondary development. Users can customize and optimize according to their own needs.

OpenVoiceChat
OpenVoiceChat is an open source project that aims to provide a platform for natural speech conversations with large language models (LLM). It supports multiple speech recognition (STT), text-to-speech (TTS) and LLM models, allowing users to interact with AI through speech. The project adopts the Apache-2.0 license, emphasizing openness and ease of use, and aims to become an open source alternative to closed commercial implementations.

Audio Chat
Audio Chat is a website focused on audio file processing. It allows users to upload audio files such as lectures, meetings, or interviews, and conduct conversation analysis. This product uses advanced audio processing technology to help users quickly obtain the key points of conversation content and improve learning and work efficiency.

LSLM
Listening-while-Speaking Language Model (LSLM) is an artificial intelligence dialogue model designed to improve the naturalness of human-computer interaction. Through full-duplex modeling (FDM) technology, it achieves the ability to listen while speaking, enhancing real-time interactivity, especially the ability to be interrupted and respond in real-time when the generated content is not satisfactory. LSLM adopts a token-based decoder with only TTS for speech generation, and a streaming self-supervised learning (SSL) encoder for real-time audio input, and explores the optimal interaction balance through three fusion strategies (early fusion, mid-term fusion, and late fusion).

Play.ai
Play.ai is an advanced voice interaction platform that leverages artificial intelligence technology to provide users with a smooth, natural conversation experience. The platform can not only understand user instructions, but also respond intelligently based on context to provide users with personalized services. The main advantage of Play.ai is its high degree of interactivity and intelligence. It can adapt to the needs of different users and provide customized conversation services. In addition, Play.ai is easy to use and quick to respond, making it a powerful tool for businesses and individuals to improve communication efficiency.
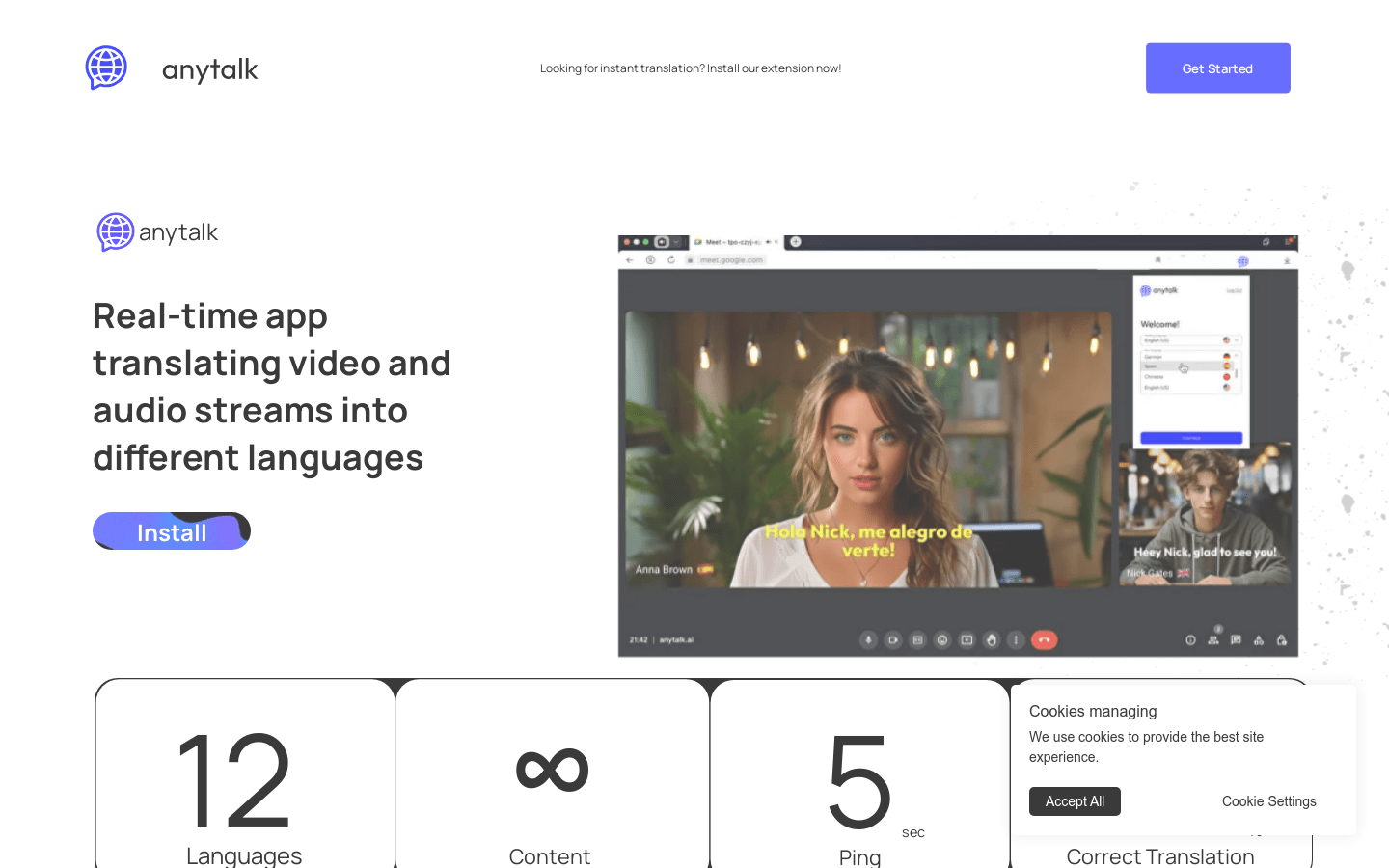
Anytalk
Anytalk is a real-time translation and dubbing tool that supports instant translation in multiple languages. It is installed via a browser extension and has the ability to translate video and audio streams into different languages. Anytalk provides an accurate translation rate of up to 97% and maintains the original sound.

Actual Chat
Actual Chat is an application that combines real-time voice, instant transcription, and artificial intelligence assistance, allowing you to communicate faster, respond in detail, and waste no time waiting. It reimagines phone calls, text and voice messaging, blending voice and text into a single medium. Through Actual Chat, you can watch the voice transcription in real time, choose to listen or read, join the conversation at any time, participate in the chat anonymously, keep conversation records, improve clarity, perfect spoken language, and improve conversation quality, including applications in scenarios such as home, work, webinars, online courses, and customer support.

GPTOnCall
GPTOnCall is an AI phone assistant product. By dialing the phone number (786) 829-7341, you can have a voice conversation with ChatGPT and get answers, suggestions and other services anytime and anywhere. Whether you're driving, running, biking, or have visual or mobility impairments, you can easily communicate with an AI chatbot. Subscribe now to experience the convenience and fun brought by this innovative technology! A free trial is available for your first consultation.