VoiSpark
A platform for generating natural speech, cloning voices and customizing AI voices.
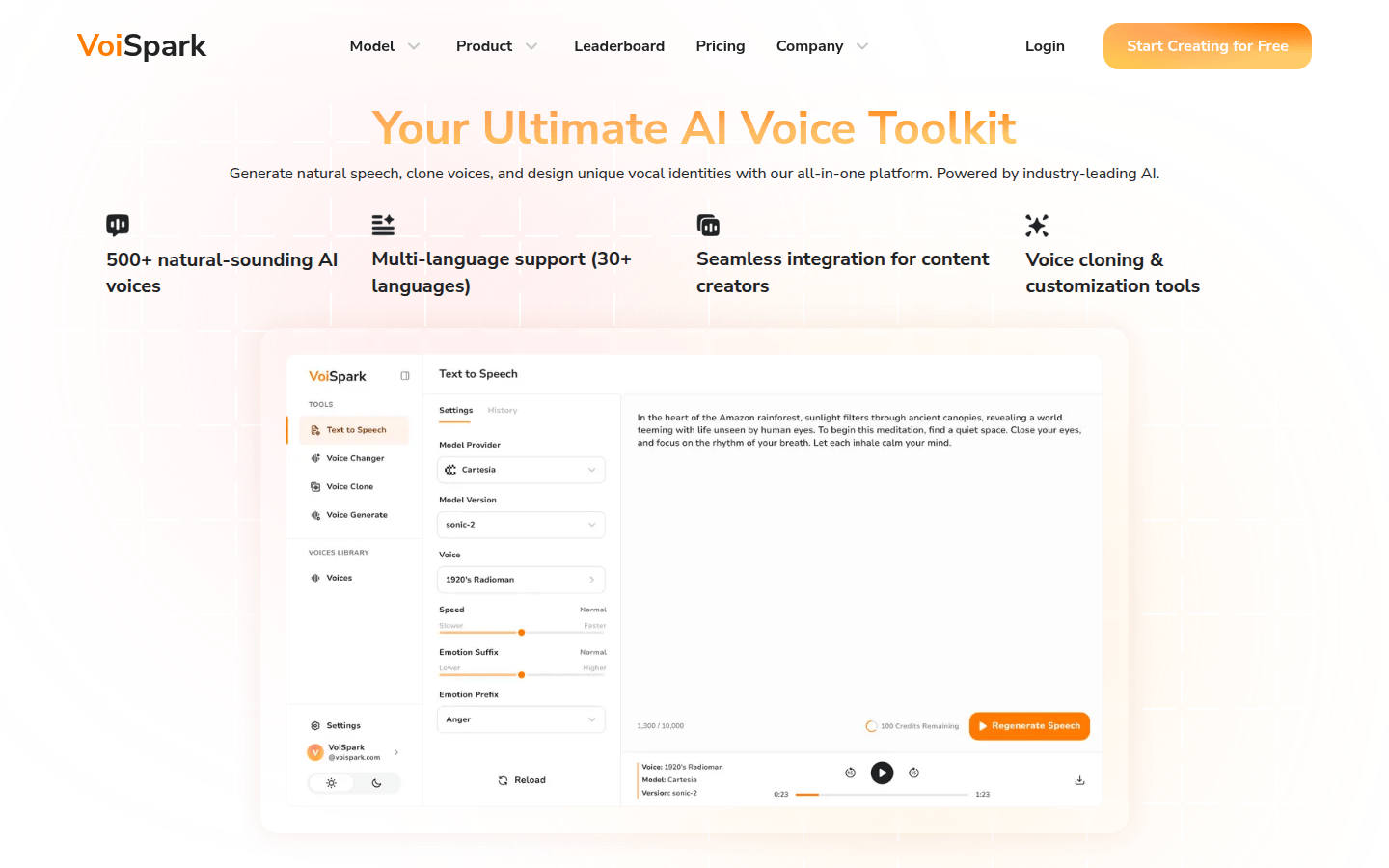
Product Details
VoiSpark is an AI voice generation platform that can generate realistic text-to-speech, clone voices, and customize unique AI voices for videos, podcasts, and more. The platform has a 100% free trial.
Main Features
How to Use
Target Users
VoiSpark is suitable for content creators, video producers and podcasters who want to add natural sounds to their creative works through artificial intelligence technology.
Examples
Video producers use VoiSpark to generate video dubbing.
Podcasters use VoiSpark to record natural sounds for their shows.
Content creators use VoiSpark to customize unique AI voices for their works.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

Kokoro-82M
Kokoro-82M is a text-to-speech (TTS) model created by hexgrad and hosted on Hugging Face. It has 82 million parameters and is open source using the Apache 2.0 license. The model released v0.19 on December 25, 2024, and provides 10 unique voice packs. Kokoro-82M ranked first in TTS Spaces Arena, showing its efficiency in parameter scale and data usage. It supports US English and British English and can be used to generate high-quality speech output.

TangoFlux
TangoFlux is an efficient text-to-audio (TTA) generation model with 515M parameters, capable of generating up to 30 seconds of 44.1kHz audio in only 3.7 seconds on a single A40 GPU. This model solves the challenge of TTA model alignment by proposing the CLAP-Ranked Preference Optimization (CRPO) framework, which enhances TTA alignment by iteratively generating and optimizing preference data. TangoFlux achieves state-of-the-art performance on both objective and subjective benchmarks, and all code and models are open source to support further research on TTA generation.

CosyVoice speech generation large model 2.0-0.5B
CosyVoice speech generation large model 2.0-0.5B is a high-performance speech synthesis model that supports zero-sample, cross-language speech synthesis and can directly generate corresponding speech output based on text content. This model is provided by Tongyi Laboratory and has powerful speech synthesis capabilities and a wide range of application scenarios, including but not limited to smart assistants, audio books, virtual anchors, etc. The importance of the model lies in its ability to provide natural and smooth speech output, which greatly enriches the human-computer interaction experience.

Hyakuhoon
Baibaoyin is an online free text-to-speech dubbing synthesis software that provides nearly a hundred dubbing templates, focusing on film and television commentary dubbing, feature film dubbing, advertising dubbing, etc. It has the advantage of being highly customized and can customize various timbre styles according to user needs.

VoiceBar
VoiceBar provides the most realistic AI speech synthesis service, including multiple languages and accents, with advanced voice quality and realism. No subscription required and usage is extremely competitive. Suitable for voice messages, multi-language text-to-speech, TikTok, explanation videos, learning and other scenarios.

Suno all in one
Suno is an efficient AI tool that converts text into music, making music creation easier. It provides the generation of various music styles and sound effects, supporting fast and convenient music creation. Suno is committed to providing creators with convenient music creation tools to help them generate high-quality music and sound effects more easily.

Stability AI text-to-speech models
Stability AI high-fidelity text-to-speech models are designed to provide natural language guidance for speech synthesis models trained on large-scale datasets. It performs natural language guidance by annotating different speaker identities, styles, and recording conditions. This method was then applied to a 45,000-hour dataset used to train speech language models. Furthermore, the model proposes simple ways to improve audio fidelity and, despite relying entirely on discovered data, performs well to a large extent.
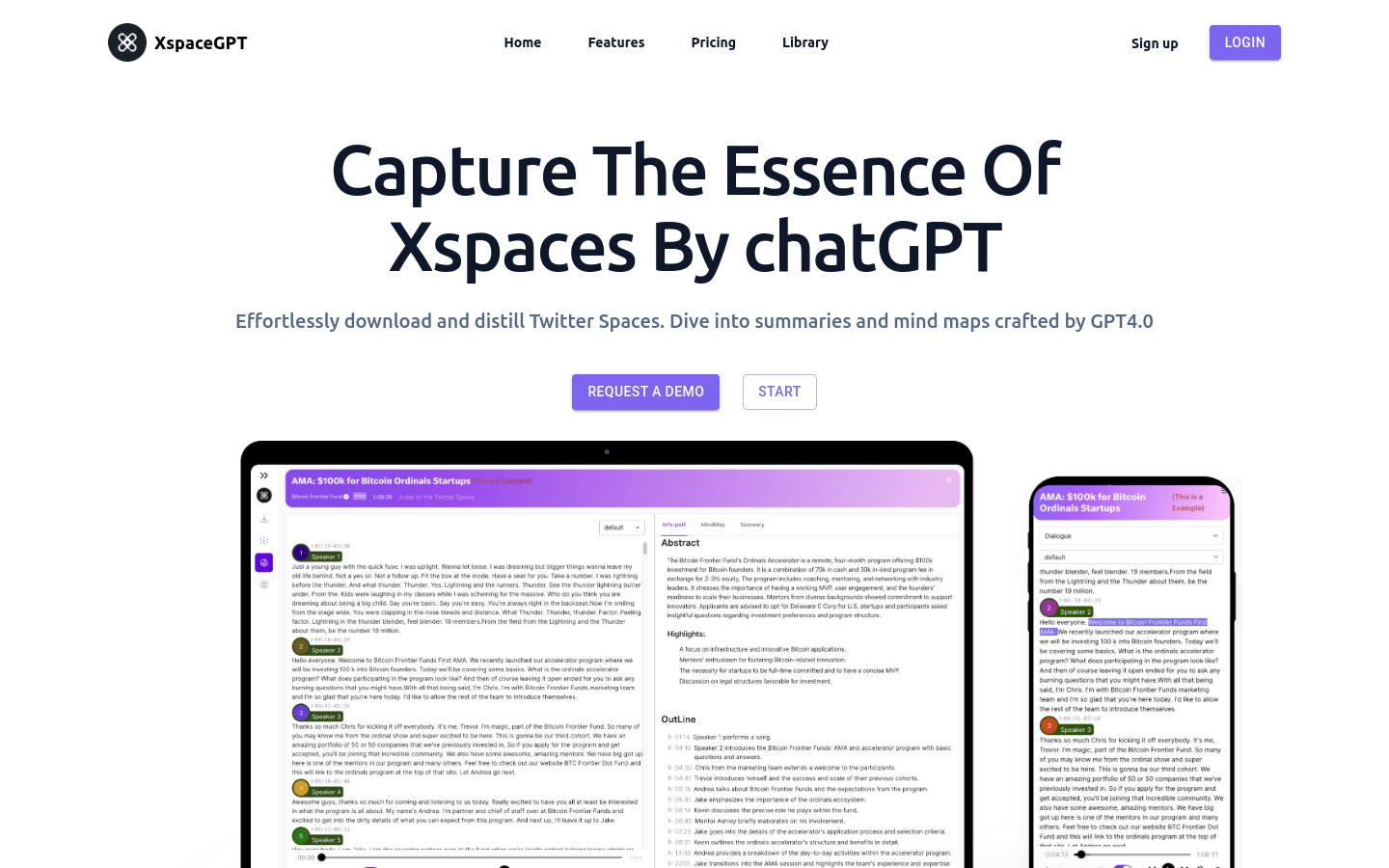
XspaceGPT
XspaceGPT is your preferred platform to convert Twitter Spaces to MP3 and text. It utilizes advanced GPT technology to quickly and reliably convert Twitter Spaces to MP3 and text and generate insightful summaries and mind maps. In addition, we also provide Twitter video downloader to convert videos to MP4 format. Fast, reliable and free.

VoiceDual
VoiceDual is an AI-based voice conversion tool that converts your voice into different languages or sound effects. Whether you want to add voiceovers in different languages to your videos or add special effects to your own voice, VoiceDual can meet your needs. The product supports more than 30 languages, allowing your voice to be easily transformed into languages from around the world. VoiceDual has flexible and reasonable pricing and is suitable for individual users and small teams. It aims to provide users with a convenient and efficient voice conversion experience.
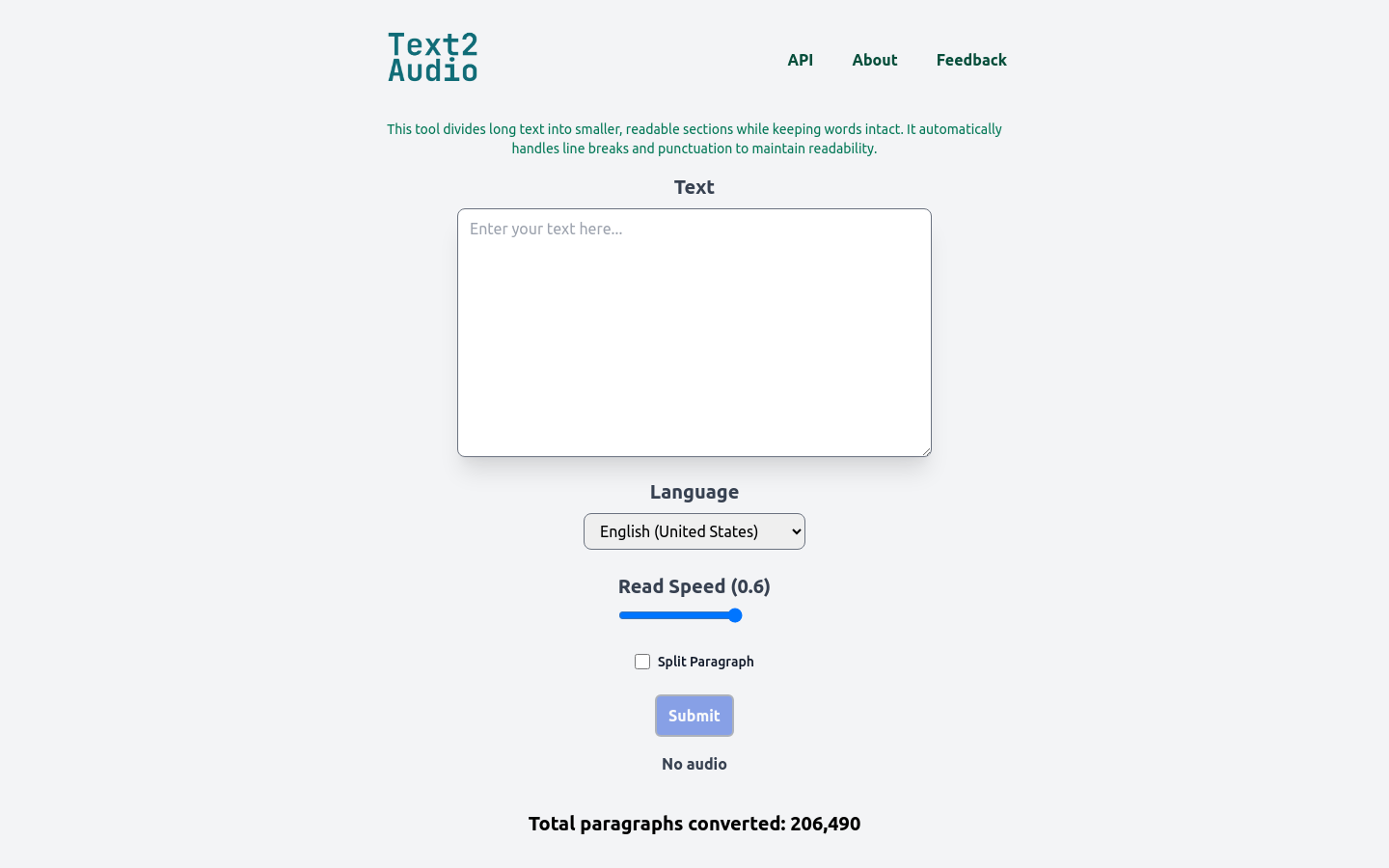
Text2Audio
Text2Audio is a free online TTS tool that can easily convert text into natural, realistic speech. No matter the purpose, it's easy to create clear, vivid speech.
Listnr AI
Listnr AI is an AI-powered voice and video generation tool. It offers over 900 voices and 142 language options to generate lifelike voice and video content. Users can get started for free and choose a paid plan if needed. Listnr AI is suitable for various scenarios, including generating videos, creating voice ads, producing audio articles, podcast production, etc. It offers transparent pricing and users can choose a suitable paid plan based on their needs.

Splash Pro
Splash Pro is an AI that generates songs in seconds using simple text prompts. It uses generative models to produce high-quality music. You can also add custom singing or rap vocals to your songs using our innovative text-to-singing voice generation AI.

Speaking AI
Speaking AI is a text-to-speech conversion tool implemented using advanced large language model technology, capable of conducting conversations with natural emotions and achieving zero-sample voice cloning. It captures your unique tone, pitch and modulation, allowing you to replicate and utilize your voice like never before. Speaking AI has achieved a breakthrough in voice cloning through advanced technology, making voice cloning sound more natural. Using Speaking AI, you can clone your own voice in just 10 seconds by recording it. We are committed to using the most advanced AI technology to promote human progress, especially in promoting the development and application of voice cloning technology.
Fluxon
Fluxon is a hyper-realistic AI speech generator that turns text into hyper-realistic sounds in any language. It can clone any sound in less than 10 minutes of sample audio. You can create dialogue using multiple voices in the same audio file. You can also create lip-sync videos by training custom voices to synthesize a single sound. Fluxon provides a REST API to integrate AI speech generation into your application. It can be used for various purposes, such as adding professional and realistic voiceovers to marketing and presentation videos, generating clear and high-quality audiobooks from text, generating realistic human voices for NPCs, creating professional translations for content, creating more natural voices for chatbots, automatically converting any text content into podcasts, etc.
Acoust
Acoust is a powerful text-to-speech (TTS) service that uses the latest AI technology to generate natural-sounding audio. It offers over 200 voices in over 30 languages and allows users to download audio files in MP3, WAV and OGG formats. With Acoust, you can create professional voiceovers for videos, narrate audiobooks, and enhance training materials. The service is fast, affordable and easy to use.

Leelo AI
Leelo AI is a leading AI speech generator that leverages advanced speech technology to provide text-to-speech services for various needs. Whether you're an animation voiceover company, a video producer looking for text-to-speech on YouTube, or need a powerful AI reading solution, Leelo AI provides seamless conversion in over 140 languages. Discover the future of sound now!