GPTEval3D
Open source 3D generative model evaluation tool

Product Details
GPTEval3D is an open source 3D generative model evaluation tool that implements automatic evaluation of text-to-3D generative models based on GPT-4V. It can calculate the ELO score of the generated model and compare and rank it with existing models. This tool is simple and easy to use, supports user-defined evaluation data sets, can give full play to the evaluation effect of GPT-4V, and is a powerful tool for studying 3D generation tasks.
Main Features
Target Users
Evaluate the effect of text to 3D generated model
Examples
Use GPTEval3D to evaluate your own trained 3D generative models
Organize multiple 3D generation models and use GPTEval3D to conduct comparative experiments
According to research needs, build a custom evaluation set and obtain the ranking of the generated model on this set.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

DreamMesh4D
DreamMesh4D is a new framework that combines mesh representation and sparsely controlled deformation technology to generate high-quality 4D objects from monocular videos. This technique solves the challenges of traditional methods in terms of spatial-temporal consistency and surface texture quality by incorporating implicit Neural Radiation Fields (NeRF) or explicit Gaussian rendering as the underlying representation. DreamMesh4D uses inspiration from modern 3D animation pipelines to bind Gaussian drawing to triangular mesh surfaces, enabling differentiable optimization of textures and mesh vertices. The framework starts from a coarse mesh provided by a single-image 3D generation method and constructs a deformation map by uniformly sampling sparse points to improve computational efficiency and provide additional constraints. Through two-stage learning, combined with reference view photometric loss, score distillation loss, and other regularization losses, the learning of static surface Gaussians and mesh vertices and dynamic deformation networks is achieved. DreamMesh4D outperforms previous video-to-4D generation methods in terms of rendering quality and spatial-temporal consistency, and its mesh-based representation is compatible with modern geometry pipelines, demonstrating its potential in the 3D gaming and film industries.

Flex3D
Flex3D is a two-stage process that generates high-quality 3D assets from a single image or text prompt. This technology represents the latest advancement in the field of 3D reconstruction and can significantly improve the efficiency and quality of 3D content generation. The development of Flex3D is supported by Meta and team members with deep backgrounds in 3D reconstruction and computer vision.

ViewCrafter
ViewCrafter is a novel approach that exploits the generative power of video diffusion models and the coarse 3D cues provided by point-based representations to synthesize high-fidelity new views of universal scenes from single or sparse images. This method gradually expands the area covered by 3D clues and new perspectives through iterative view synthesis strategies and camera trajectory planning algorithms, thereby expanding the range of new perspective generation. ViewCrafter can facilitate various applications such as immersive experiences and real-time rendering through optimized 3D-GS representation, and more imaginative content creation through scene-level text-to-3D generation.

OmniRe
OmniRe is a comprehensive approach for efficient reconstruction of high-fidelity dynamic urban scenes through device logs. This technology achieves comprehensive reconstruction of different objects in the scene by constructing a dynamic neural scene graph based on Gaussian representation and constructing multiple local specification spaces to simulate various dynamic actors including vehicles, pedestrians and cyclists. OmniRe allows us to fully reconstruct the different objects present in the scene and subsequently implement a simulation of the reconstructed scene with the participation of all participants in real time. Extensive evaluation on the Waymo dataset shows that OmniRe significantly outperforms previous state-of-the-art methods both quantitatively and qualitatively.
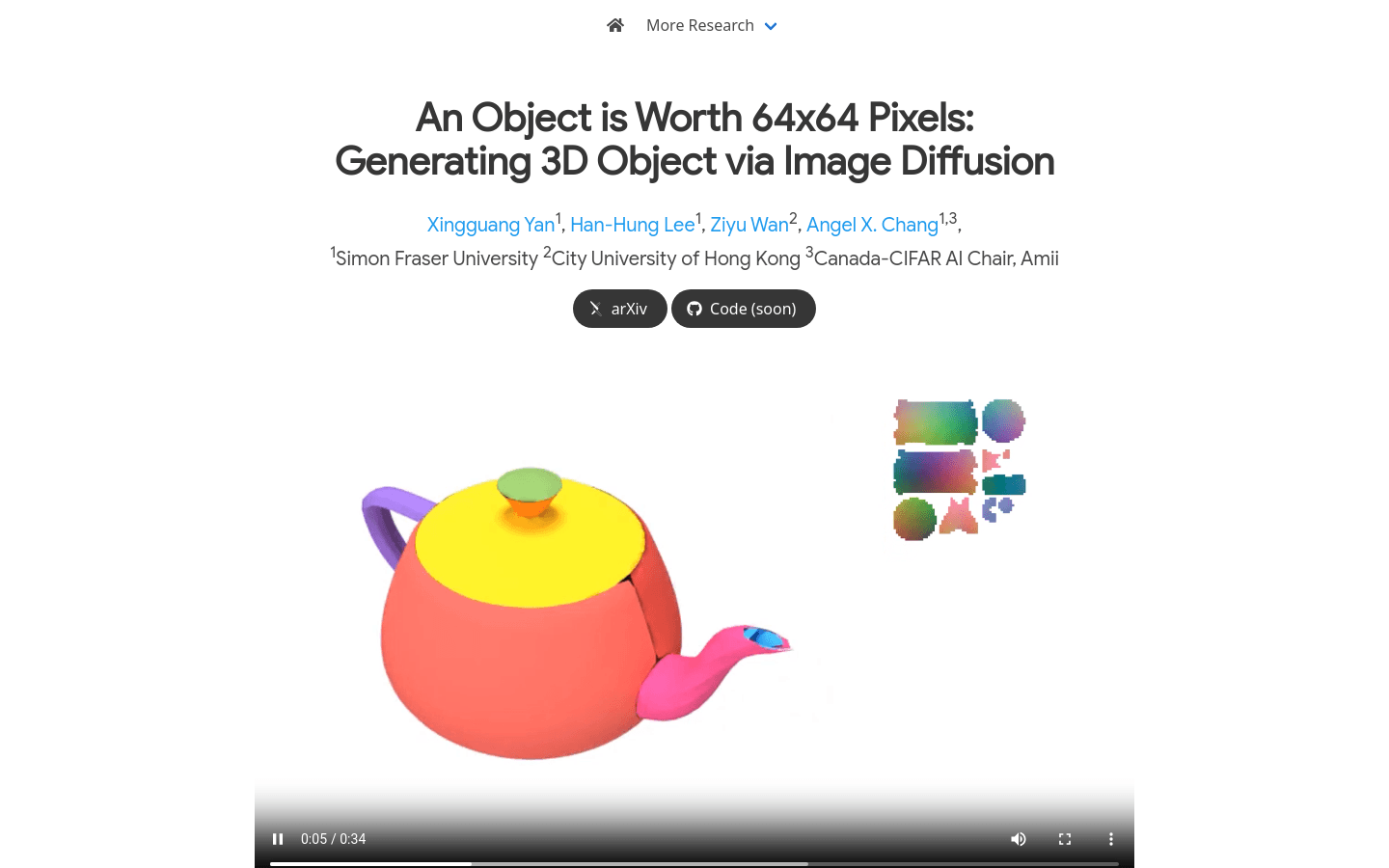
Omages
Object Images is an innovative 3D model generation technology that simplifies the generation and processing of 3D shapes by encapsulating complex 3D shapes in a 64x64 pixel image, so-called 'Object Images' or 'omages'. This technology solves the challenges of geometric and semantic irregularities in traditional polygonal meshes by using image generation models, such as Diffusion Transformers, directly for 3D shape generation.

VFusion3D
VFusion3D is a scalable 3D generative model built on pre-trained video diffusion models. It solves the problem of difficulty and limited quantity of 3D data acquisition, generates large-scale synthetic multi-view data sets by fine-tuning the video diffusion model, and trains a feed-forward 3D generation model that can quickly generate 3D assets from a single image. The model performed well in user studies, with users preferring results generated by VFusion3D more than 90% of the time.

SAM-Graph
SAM-guided Graph Cut for 3D Instance Segmentation is a deep learning method that utilizes 3D geometry and multi-view image information for 3D instance segmentation. This method effectively utilizes 2D segmentation models for 3D instance segmentation through a 3D to 2D query framework, constructs superpoint graphs through graph cut problems, and achieves robust segmentation performance for different types of scenes through graph neural network training.

TexGen
TexGen is an innovative multi-view sampling and resampling framework for synthesizing 3D textures from arbitrary textual descriptions. It utilizes pre-trained text-to-image diffusion models, multi-view sampling strategies through consistent view sampling and attention guidance, and noise resampling techniques to significantly improve the texture quality of 3D objects with a high degree of view consistency and rich appearance details.

SF3D
SF3D is a deep learning-based 3D asset generation model that can quickly generate textured 3D models with UV unwrapping and material parameters from a single image. Compared with traditional methods, SF3D is specially trained for mesh generation and integrates fast UV unwrapping technology to quickly generate textures instead of relying on vertex colors. In addition, the model learns material parameters and normal maps to improve the visual quality of the reconstructed model. SF3D also introduces a delighting step that effectively removes low-frequency lighting effects, ensuring that the reconstructed mesh is easy to use under new lighting conditions.
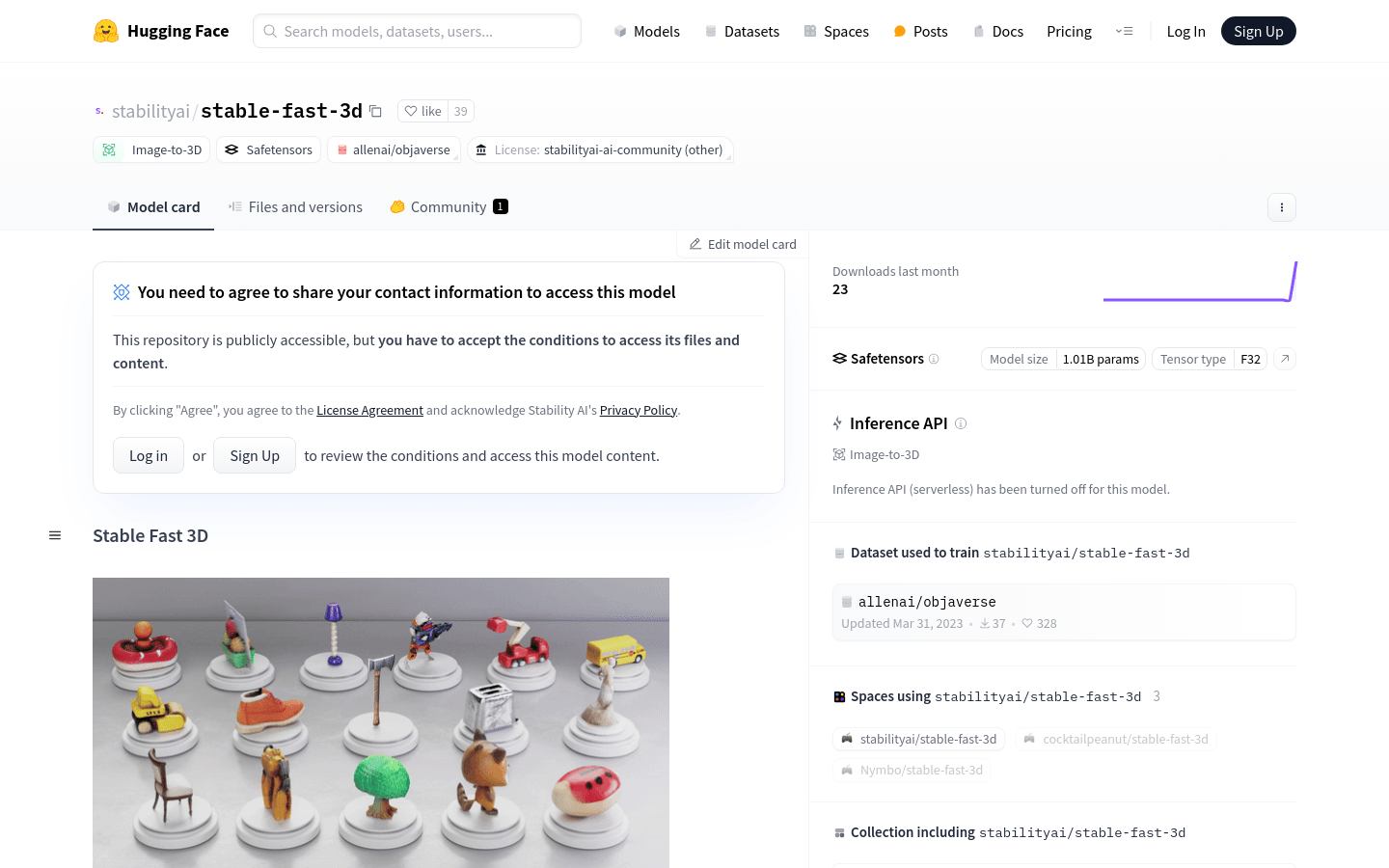
Stable Fast 3D
Stable Fast 3D (SF3D) is a large-scale reconstruction model based on TripoSR that can generate textured UV unwrapped 3D mesh assets from a single object image. The model is trained to create 3D models in less than a second, has a low polygon count, and is UV unwrapped and textured, making the model easier to use in downstream applications such as game engines or rendering work. In addition, the model predicts each object’s material parameters (roughness, metallic feel), enhancing reflection behavior during rendering. SF3D is suitable for fields that require rapid 3D modeling, such as game development, movie special effects production, etc.
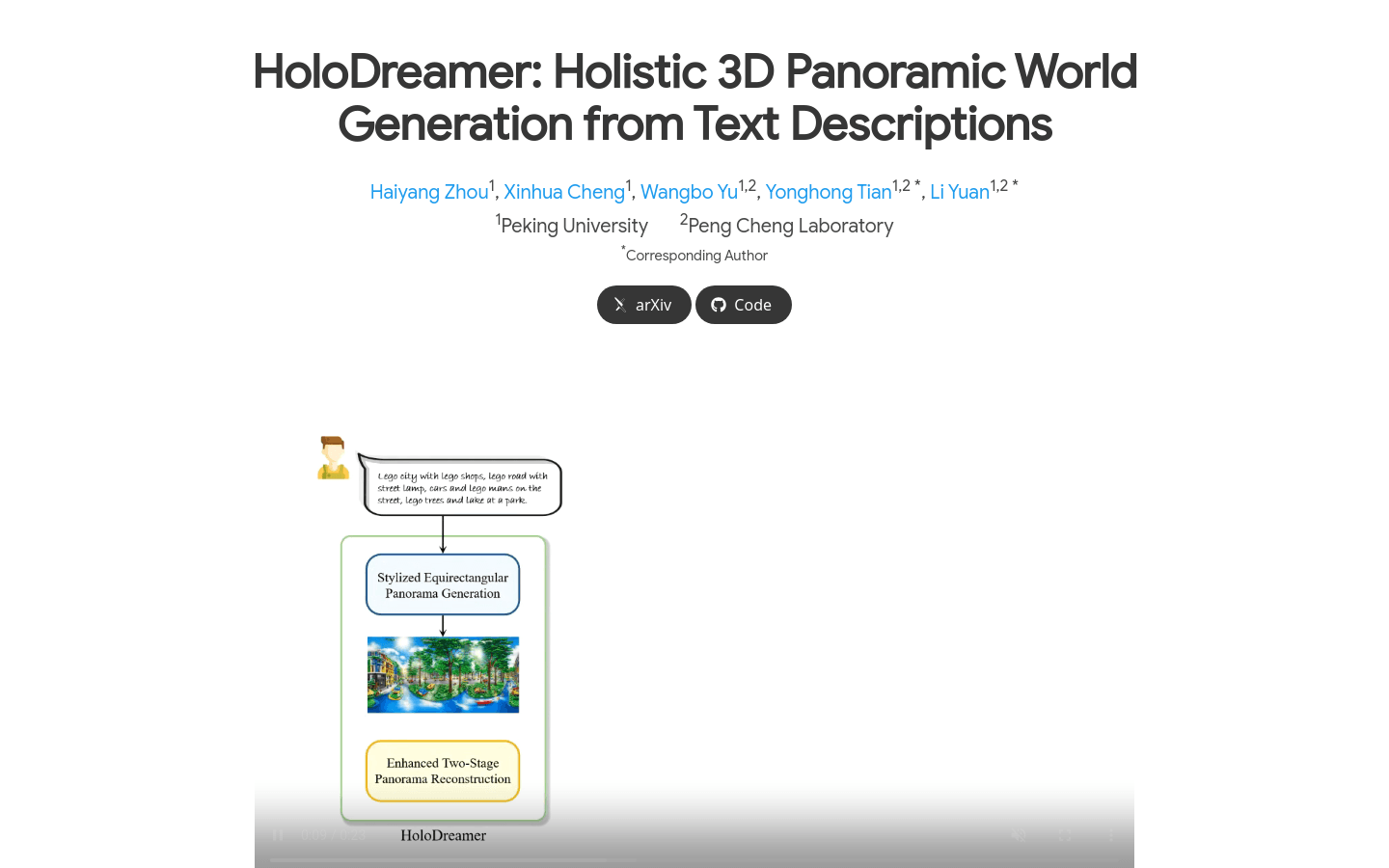
HoloDreamer
HoloDreamer is a text-driven 3D scene generation framework that can generate immersive and perspective-consistent fully enclosed 3D scenes. It consists of two basic modules: stylized equirectangular panorama generation and enhanced two-stage panorama reconstruction. The framework first generates a high-definition panorama as an overall initialization of a complete 3D scene, and then utilizes 3D Gaussian Scattering (3D-GS) technology to quickly reconstruct the 3D scene, thereby achieving viewpoint-consistent and fully enclosed 3D scene generation. The main advantages of HoloDreamer include high visual consistency, harmony and robustness of reconstruction quality and rendering.

VGGSfM
VGGSfM is a deep learning-based 3D reconstruction technology designed to reconstruct the camera pose and 3D structure of a scene from an unrestricted set of 2D images. This technology enables end-to-end training through a fully differentiable deep learning framework. It leverages deep 2D point tracking technology to extract reliable pixel-level trajectories while recovering all cameras based on image and trajectory features, and optimizes camera and triangulated 3D points via differentiable bundled adjustment layers. VGGSfM achieves state-of-the-art performance on three popular datasets: CO3D, IMC Phototourism and ETH3D.

Animate3D
Animate3D is an innovative framework for generating animations for any static 3D model. Its core idea consists of two main parts: 1) Propose a new multi-view video diffusion model (MV-VDM), which is based on multi-view rendering of static 3D objects and trained on the large-scale multi-view video dataset (MV-Video) we provide. 2) Based on MV-VDM, a framework combining reconstruction and 4D Scored Distillation Sampling (4D-SDS) is introduced to generate animations for 3D objects using multi-view video diffusion priors. Animate3D enhances spatial and temporal consistency by designing a new spatiotemporal attention module and maintains the identity of static 3D models through multi-view rendering. In addition, Animate3D also proposes an efficient two-stage process to animate 3D models: first directly reconstructing motion from the generated multi-view video, and then refining the appearance and motion through the introduced 4D-SDS.

CharacterGen
CharacterGen is an efficient 3D character generation framework capable of generating 3D pose-unified character meshes with high quality and consistent appearance from a single input image. It solves the challenges posed by diverse poses through a streamlined generation pipeline and image-conditioned multi-view diffusion model to effectively calibrate the input pose to a canonical form while retaining the key attributes of the input image. It also adopts a general transformer-based sparse view reconstruction model and a texture back-projection strategy to generate high-quality texture maps.

EgoGaussian
EgoGaussian is an advanced 3D scene reconstruction and dynamic object tracking technology that can simultaneously reconstruct a 3D scene and dynamically track the movement of objects through only RGB first-person perspective input. This technology leverages the unique discrete properties of Gaussian scattering to segment dynamic interactions from the background, and exploits the dynamic nature of human activity through a fragment-level online learning process to temporally reconstruct the evolution of the scene and track the motion of rigid objects. EgoGaussian surpasses previous NeRF and dynamic Gaussian methods in the challenge of wild videos and also performs well in the quality of reconstructed models.

GaussianCube
GaussianCube is an innovative 3D radiation representation method that greatly promotes the development of 3D generative modeling through structured and explicit representation. This technique achieves high-accuracy fitting by rearranging Gaussian functions into a predefined voxel grid using a novel density-constrained Gaussian fitting algorithm and an optimal transfer method. GaussianCube has fewer parameters and higher quality than traditional implicit feature decoders or spatially unstructured radiative representations, making 3D generative modeling easier.