AuraSR-v2
GAN-based image super-resolution model
Product Details
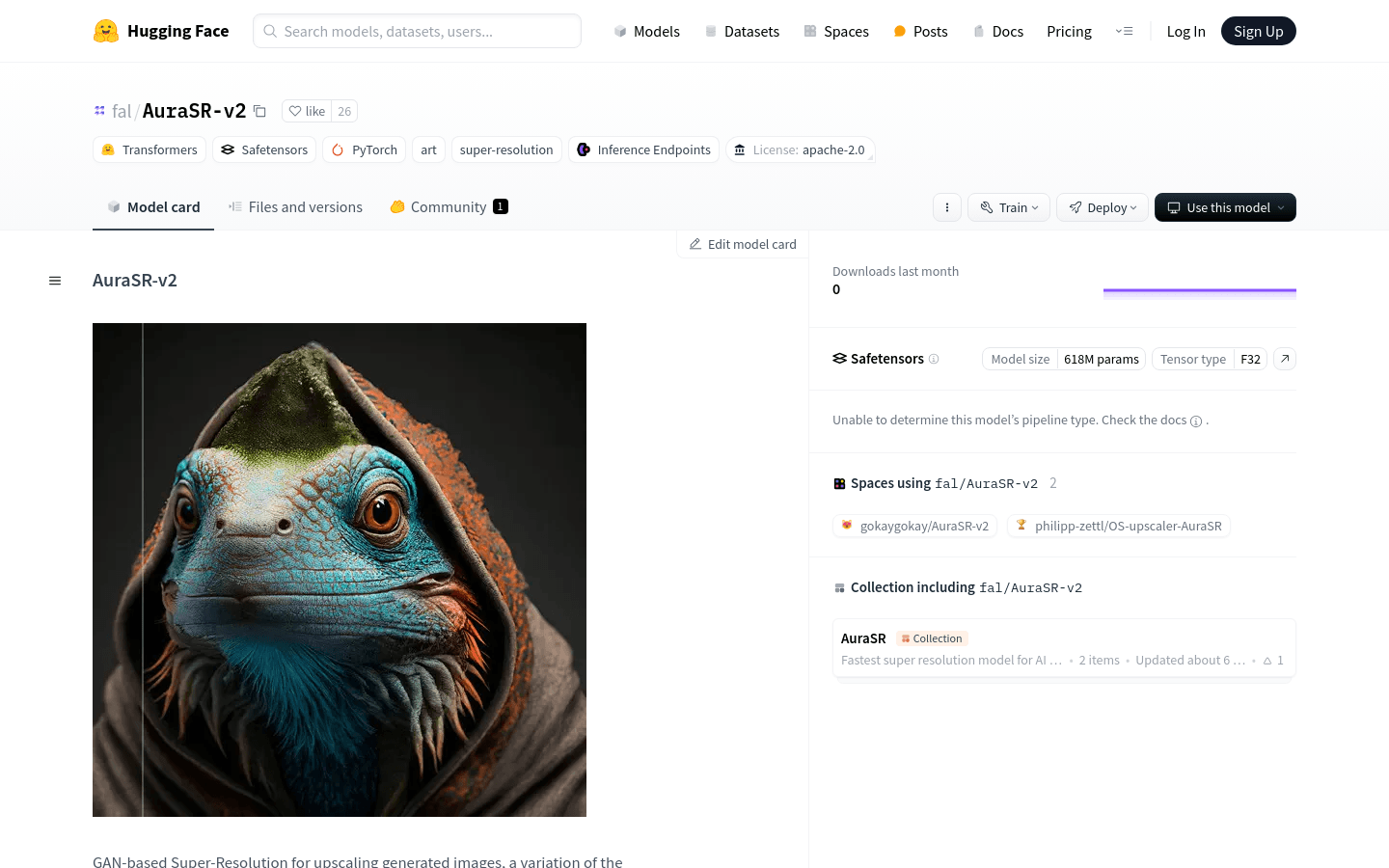
AuraSR-v2 is an image super-resolution model based on Generative Adversarial Networks (GAN), designed for enlarging generated images, and is a variant of the GigaGAN paper. The PyTorch implementation of this model is based on the unofficial lucidrains/gigagan-pytorch repository. It can significantly increase the resolution of images while maintaining image quality, which is particularly important for application scenarios that require high-definition image output.
Main Features
How to Use
Target Users
AuraSR-v2 is mainly targeted at developers and researchers who need to perform image amplification processing, including but not limited to image processing, computer vision, machine learning and other fields. This model is particularly suitable for commercial applications that require high-definition image output, such as advertising design, game development, etc.
Examples
Use AuraSR-v2 to enlarge AI-generated low-resolution images to high-definition resolution for commercial advertising display.
In game development, use AuraSR-v2 to optimize the image quality of characters and scenes.
Researchers use AuraSR-v2 to process satellite images to improve the accuracy of image analysis.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

Hallo2
Hallo2 is a portrait image animation technology based on a latent diffusion generation model that generates high-resolution, long-term videos driven by audio. It expands Hallo's capabilities by introducing several design improvements, including generating long-duration videos, 4K resolution videos, and adding the ability to enhance expression control through text prompts. Hallo2's key advantages include high-resolution output, long-term stability, and enhanced control through text prompts, which make it a significant advantage in generating rich and diverse portrait animation content.

Flux AI Img
Flux AI is a platform that utilizes advanced AI algorithms to generate high-quality images. It uses deep learning models to transform users' ideas into visual masterpieces in seconds. The platform provides features such as real-time generation, customized output, multi-language support, ethical AI and seamless integration, aiming to help users quickly realize their ideas and improve work efficiency. Background information on Flux AI shows that it is committed to responsible AI development, respecting copyright, avoiding bias, and promoting positive social impact.

ComfyGen
ComfyGen is an adaptive workflow system focused on text-to-image generation that automates and customizes efficient workflows by learning user prompts. The advent of this technology marks a shift from the use of a single model to complex workflows that combine multiple specialized components to improve the quality of image generation. The main benefit behind ComfyGen is the ability to automatically adjust the workflow based on the user's text prompts to produce higher quality images, which is important for users who need to produce images of a specific style or theme.
AnimeGen
AnimeGen is an online tool that uses advanced AI models to convert text prompts into anime-style images. It provides users with a simple and fast way to generate high-quality animation pictures through complex algorithms and machine learning technology, which is very suitable for artists, content creators and animation enthusiasts to explore new creative possibilities. AnimeGen supports more than 80 languages, and the generated images are publicly displayed and can be crawled by search engines. It is a multi-functional creative tool.

AnyPhoto.co
AnyPhoto.co is an online platform that uses artificial intelligence technology to provide photo stylization and artistic effects. It achieves efficient model adaptability, fine style control, fast processing speed and excellent image quality through LoRA (Low Rank Adaptation) technology. Users can upload their own portrait photos, easily convert them into hand-drawn sketches, and try out a variety of unique painting styles to create one-of-a-kind works of art. The platform has a friendly interface, supports personalized adjustments, and provides highly complete output, making it very suitable for users who require fast, high-quality image processing.
ComfyUI-Fluxtapoz
ComfyUI-Fluxtapoz is a collection of nodes designed for Flux to edit images in ComfyUI. It allows users to edit and style images through a series of node operations, and is especially suitable for professionals who need to perform image processing and creative work. This project is currently open source and follows the GPL-3.0 license agreement, which means that users can freely use, modify and distribute the software, but they need to comply with the relevant provisions of the open source license.

Toy Box Flux
Toy Box Flux is a 3D rendering model trained on AI-generated images, which combines the weights of existing 3D LoRA models and Coloring Book Flux LoRA to form a unique style. This model is particularly suitable for generating images of toy designs with a specific style. It performs best on objects and human subjects, with animal performance erratic due to insufficient data in the training images. In addition, the model can improve the realism of indoor 3D renderings. There are plans to strengthen the consistency of this style in v2 by mixing more generated and pre-existing output.

DisEnvisioner
DisEnvisioner is an advanced image generation technology that isolates and enhances subject features to generate customized images without tedious adjustments or reliance on multiple reference images. This technology effectively distinguishes and enhances subject features while filtering out irrelevant attributes, achieving superior personalization quality in terms of editability and identity preservation. The research background of DisEnvisioner is based on the current need in the field of image generation for extracting subject features from visual cues. It solves the challenges of existing technologies in this field through innovative methods.

Animate-X
Animate-X is a universal LDM-based animation framework for various character types (collectively referred to as X), including human mimic characters. This framework enhances motion representation by introducing pose indicators, which can more comprehensively capture motion patterns from driving videos. Key benefits of Animate-X include in-depth modeling of motion, the ability to understand the motion patterns driving video and flexibly apply them to target characters. In addition, Animate-X introduces a new Animated Anthropomorphic Benchmark (A2Bench) to evaluate its performance on general and widely applicable animated images.

RealAnime
RealAnime - Detailed V1 is a LoRA model based on Stable Diffusion, specifically designed to generate realistic anime-style images. Through deep learning technology, this model can understand and generate high-quality animation character images to meet the needs of animation enthusiasts and professional illustrators. Its importance lies in its ability to greatly improve the efficiency and quality of animation-style image generation and provide strong technical support for the animation industry. Currently, the model is provided on the Tensor.Art platform, and users can use it online without downloading and installing, which is convenient and fast. In terms of price, users can unlock download benefits by purchasing the Buffet plan and enjoy more flexible usage.

FacePoke
FacePoke is an AI-powered real-time head and face transformation tool that allows users to manipulate facial features through an intuitive drag-and-drop interface, breathing life into portraits for realistic animations and expressions. FacePoke utilizes advanced AI technology to ensure that all edits maintain a natural and realistic appearance, while automatically adjusting surrounding facial areas to maintain the overall integrity of the image. This tool stands out for its user-friendly interface, real-time editing capabilities, and advanced AI-driven adjustments, making it suitable for users of all skill levels, whether they are professional content creators or beginners.

Meissonic
Meissonic is a non-autoregressive masked image modeling text-to-image synthesis model capable of generating high-resolution images. It is designed to run on consumer grade graphics cards. The importance of this technology lies in its ability to utilize existing hardware resources to provide users with a high-quality image generation experience while maintaining high operating efficiency. Background information on Meissonic includes its paper published on arXiv, and its model and code on Hugging Face.

CogView3-Plus-3B
The text-to-image generation model developed by the Tsinghua University team is open source, has broad application prospects in the field of image generation, and has the advantages of high-resolution output.

Flux Ghibsky Illustration
Flux Ghibsky Illustration is a text-based image generation model that combines the fantastical details of Hayao Miyazaki's animation studio with the serene skies of Makoto Shinkai's work to create enchanting scenes. This model is particularly suitable for creating fantastic visual effects, and users can generate images with a unique aesthetic through specific trigger words. It is an open source project based on the Hugging Face platform, allowing users to download models and run them on Replicate.

Easy Anime Maker
Easy Anime Maker is an artificial intelligence-based animation generator that uses deep learning techniques such as generative adversarial networks to convert user-entered text descriptions or uploaded photos into anime-style artwork. The importance of this technology is that it lowers the threshold for creating animation art, allowing users without professional painting skills to create personalized animation images. Product background information shows that it is an online platform where users can generate anime art through simple text prompts or uploading photos, making it ideal for anime enthusiasts and professionals who need to quickly generate anime-style images. The product provides a free trial, and users can get 5 free points after registration. If you need more generation needs, you can choose to purchase points without subscribing.

Image Describer
Image Describer is a tool that uses artificial intelligence technology to upload images and output image descriptions according to user needs. It understands image content and generates detailed descriptions or explanations to help users better understand the meaning of the image. This tool is not only suitable for ordinary users, but also helps visually impaired people understand the content of pictures through text-to-speech function. The importance of the image description generator lies in its ability to improve the accessibility of image content and enhance the efficiency of information dissemination.