openai-realtime-api
TypeScript client for OpenAI’s real-time speech API.

Product Details
openai-realtime-api is a TypeScript client for interacting with OpenAI's real-time speech API. It provides strongly typed features and is a perfect replacement for the official JavaScript version of OpenAI. The client fixes many minor bugs and inconsistencies and is fully compatible with official and unofficial events. It supports Node.js, browser, Deno, Bun, CF workers and other environments, and has been published to NPM. The importance of this technology lies in its ability to provide developers with a safer and more convenient way to integrate and use OpenAI’s real-time speech capabilities, especially when large amounts of data and requests need to be processed.
Main Features
How to Use
Target Users
The target audience is mainly developers and software engineers, especially professionals who need to integrate real-time speech capabilities in their projects. Since it supports multiple environments, it is an ideal choice for developers who need a cross-platform solution. In addition, due to its strongly typed nature, it is also suitable for developers who pay attention to code quality and maintainability.
Examples
Developers can use this API client to create a real-time voice chat application in a Node.js environment.
In the browser, developers can use the client to implement an interactive interface for speech recognition and generation.
Through the relay server, developers can use OpenAI's real-time voice capabilities in environments that do not support direct API calls, such as certain restricted browsers or mobile applications.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

Reverb
Reverb is an open source speech recognition and speaker segmentation model inference code that uses the WeNet framework for speech recognition (ASR) and the Pyannote framework for speaker segmentation. It provides detailed model descriptions and allows users to download models from Hugging Face. Reverb aims to provide developers and researchers with high-quality speech recognition and speaker segmentation tools to support a variety of speech processing tasks.

Realtime API
Realtime API is a low-latency voice interaction API launched by OpenAI that allows developers to build fast voice-to-speech experiences in applications. The API supports natural speech-to-speech conversations and handles interruptions, similar to ChatGPT’s advanced speech mode. It connects through WebSocket and supports function calls, allowing the voice assistant to respond to user requests, trigger actions or introduce new context. The launch of this API means that developers no longer need to combine multiple models to build a voice experience, but can achieve a natural conversation experience through a single API call.

Deepgram Voice Agent API
The Deepgram Voice Agent API is a unified speech-to-speech API that allows natural-sounding conversations between humans and machines. The API is powered by industry-leading speech recognition and speech synthesis models to listen, think and speak naturally and in real time. Deepgram is committed to driving the future of voice-first AI through its voice agent API, integrating advanced generative AI technology to create a business world capable of smooth, human-like voice agents.
speech-to-speech
speech-to-speech is an open source modular GPT4-o project that implements speech-to-speech conversion through continuous parts such as speech activity detection, speech-to-text, language model, and text-to-speech. It leverages the Transformers library and models available on the Hugging Face hub, providing a high degree of modularity and flexibility.

whisper-diarization
Whisper-diarization is an open source project that combines Whisper's automatic speech recognition (ASR) capabilities, vocal activity detection (VAD), and speaker embedding technology. It improves the accuracy of speaker embeddings by extracting the sound parts in the audio, then using Whisper to generate transcripts and correcting timestamps and alignments with WhisperX to reduce segmentation errors due to time offsets. Next, MarbleNet is used for VAD and segmentation to exclude silence, TitaNet is used to extract speaker embeddings to identify the speaker of each paragraph, and finally the results are associated with timestamps generated by WhisperX, the speaker of each word is detected based on the timestamp, and realigned using a punctuation model to compensate for small temporal shifts.

voicechat2
voicechat2 is a fast, fully localized AI voice chat application based on WebSocket, enabling users to achieve voice-to-voice instant messaging in their local environment. It uses AMD RDNA3 graphics card and Faster Whisper technology to significantly reduce the delay of voice communication and improve communication efficiency. This product is suitable for developers and technicians who need fast response and real-time communication.
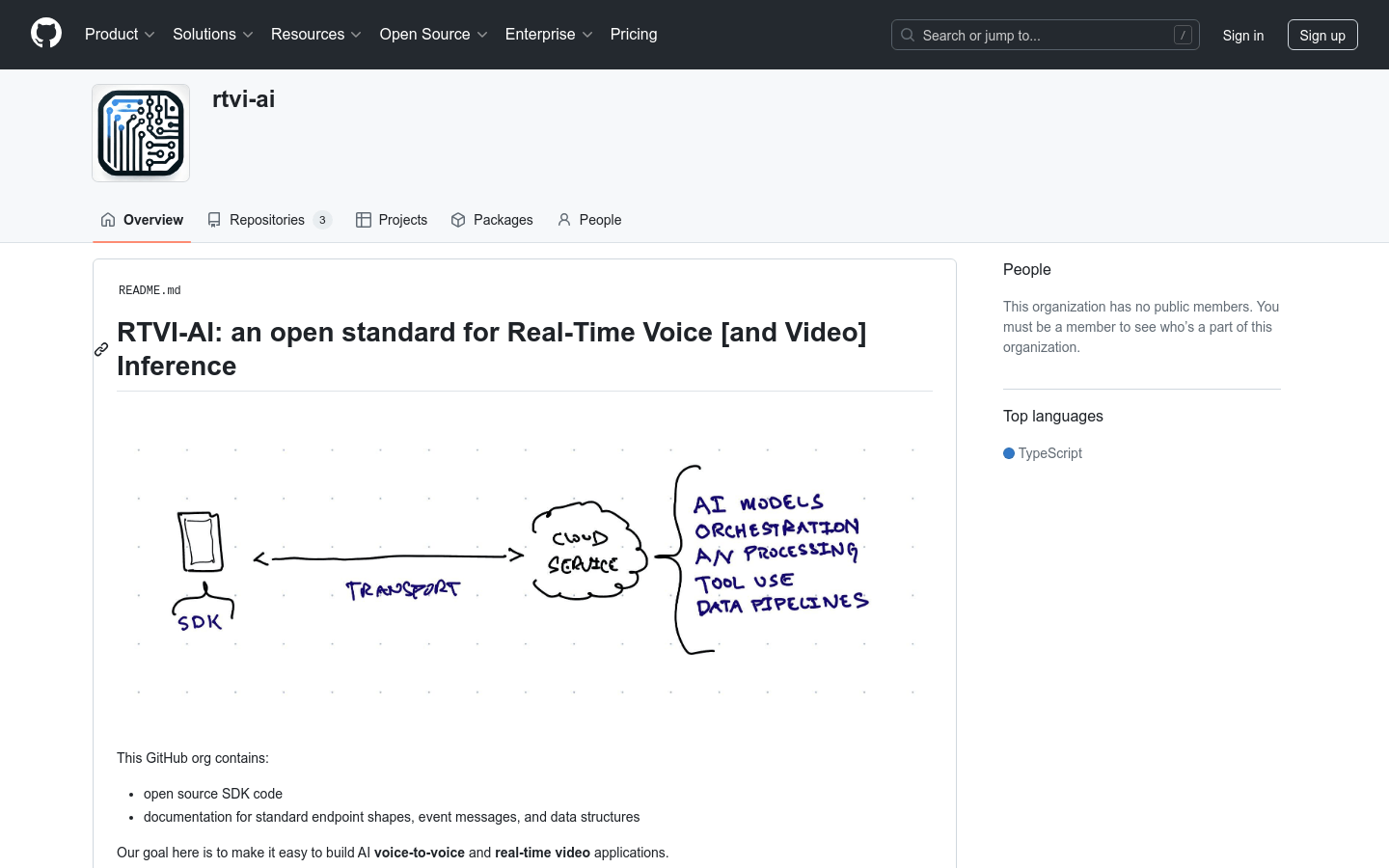
RTVI-AI
RTVI-AI is an open standard designed to simplify building AI voice-to-speech and real-time video applications. It provides open source SDK code and documentation of standard endpoint shapes, event messages, and data structures, enabling developers to use any inference service and allowing inference services to leverage open source tools to develop complex client tools for real-time multimedia.

ChatTTS_Speaker
ChatTTS_Speaker is an experimental project based on the ERes2NetV2 speaker recognition model. It aims to score the stability and label the timbre to help users choose a timbre that is stable and meets their needs. The project is open source and supports online listening and downloading of sound samples.

sherpa-onnx
sherpa-onnx is a speech recognition and speech synthesis project based on the next generation Kaldi. It uses onnxruntime for inference and supports a variety of speech-related functions, including speech-to-text (ASR), text-to-speech (TTS), speaker recognition, speaker verification, language recognition, keyword detection, etc. It supports multiple platforms and operating systems, including embedded systems, Android, iOS, Raspberry Pi, RISC-V, servers, and more.
LookOnceToHear
LookOnceToHear is an innovative smart headphone interaction system that allows users to select the target speaker they want to hear through simple visual recognition. This technology received an honorable mention for Best Paper at CHI 2024. It achieves real-time speech extraction by synthesizing audio mixes, head-related transfer functions (HRTFs) and binaural room impulse responses (BRIRs), providing users with a novel way to interact.
AV-HuBERT
AV-HuBERT is a self-supervised representation learning framework specifically designed for audiovisual speech processing. It achieves state-of-the-art lip reading, automatic speech recognition (ASR) and audio-visual speech recognition results on the LRS3 audio-visual speech benchmark. This framework learns audio-visual speech representation through masked multi-modal cluster prediction and provides robust self-supervised audio-visual speech recognition.

VSP-LLM
VSP-LLM is a framework that combines visual speech processing (Visual Speech Processing) and large language models (LLMs), aiming to maximize context modeling capabilities through the powerful capabilities of LLMs. VSP-LLM is designed to perform the multi-tasking of visual speech recognition and translation by mapping the input video to the input latent space of the LLM through a self-supervised visual speech model. This framework enables efficient training by proposing a novel deduplication method and low-rank adapter (LoRA).

SpeechGPT
SpeechGPT is a multimodal language model with inherent cross-modal dialogue capabilities. It can sense and generate multimodal content and follow multimodal human instructions. SpeechGPT-Gen is a speech generation model that extends the information chain. SpeechAgents is a human communication simulation with a multi-modal multi-agent system. SpeechTokenizer is a unified speech tokenizer for speech language models. Release dates and related information for these models and datasets can be found on the official website.