Oasis
Real-time open world AI model based on Transformer

Product Details
Oasis is the first playable, real-time, open-world AI model developed by Decart AI. It is an interactive video game generated end-to-end by Transformer on a frame-by-frame basis. Oasis can receive user keyboard and mouse input, generate gameplay in real time, and internally simulate physics, game rules and graphics. The model learns from direct observation of gameplay, allowing users to move, jump, pick up items, break blocks, and more. Oasis is seen as the first step in researching a basic model for a more complex interactive world, which may replace traditional game engines in the future. The implementation of Oasis requires improvements in model architecture and breakthroughs in model reasoning technology to achieve real-time interaction between users and models. Decart AI adopts the latest diffusion training and Transformer model methods, and combines large language models (LLMs) to train an autoregressive model that can generate videos based on the user's instant actions. In addition, Decart AI has developed a proprietary inference framework to deliver peak utilization of NVIDIA H100 Tensor Core GPUs and support Etched's upcoming Sohu chips.
Main Features
How to Use
Target Users
The target audience is game developers, AI researchers, and users who are interested in real-time interactive video content. Oasis provides a new platform that allows developers to create and simulate complex game worlds, while AI researchers can explore and optimize reasoning techniques for large models. For ordinary users, Oasis provides a new experience in interactive video games, where users can influence the development of the game world in real time.
Examples
Game developers use Oasis to create a new open world game where players can influence the game environment in real time.
AI researchers use Oasis to conduct research on model training and inference technologies to optimize the performance of large AI models.
Educational institutions use Oasis as a teaching tool to allow students to experience and learn the application of AI in game development.
Quick Access
Visit Website →Categories
Related Recommendations
Discover more similar quality AI tools

HunyuanVideo
HunyuanVideo is a systematic framework open sourced by Tencent for training large-scale video generation models. By employing key technologies such as data curation, image-video joint model training, and efficient infrastructure, the framework successfully trained a video generation model with over 13 billion parameters, the largest among all open source models. HunyuanVideo performs well in visual quality, motion diversity, text-video alignment and generation stability, surpassing multiple industry-leading models including Runway Gen-3 and Luma 1.6. By open-sourcing code and model weights, HunyuanVideo aims to bridge the gap between closed-source and open-source video generation models and promote the active development of the video generation ecosystem.

CogVideoX1.5-5B-SAT
CogVideoX1.5-5B-SAT is an open source video generation model developed by the Knowledge Engineering and Data Mining Team of Tsinghua University. It is an upgraded version of the CogVideoX model. This model supports the generation of 10-second videos and supports the generation of higher-resolution videos. The model includes modules such as Transformer, VAE and Text Encoder, which can generate video content based on text descriptions. The CogVideoX1.5-5B-SAT model provides a powerful tool for video content creators with its powerful video generation capabilities and high-resolution support, especially in education, entertainment and business fields.

Mochi in ComfyUI
Mochi is Genmo's latest open source video generation model, which is optimized in ComfyUI and can be implemented even with consumer-grade GPUs. Known for its high-fidelity motion and excellent prompt following, Mochi brings state-of-the-art video generation capabilities to the ComfyUI community. Mochi models are released under the Apache 2.0 license, which means developers and creators are free to use, modify, and integrate Mochi without being hindered by a restrictive license. Mochi is able to run on consumer-grade GPUs such as the 4090, and supports multiple attention backends in ComfyUI, allowing it to fit in less than 24GB of VRAM.
FasterCache
FasterCache is an innovative no-training strategy designed to accelerate the inference process of video diffusion models and generate high-quality video content. The importance of this technology is that it can significantly improve the efficiency of video generation while maintaining or improving the quality of the content, which is very valuable for industries that need to quickly generate video content. FasterCache was developed by researchers from the University of Hong Kong, Nanyang Technological University, and Shanghai Artificial Intelligence Laboratory, and the project page provides more visual results and detailed information. The product is currently available for free and is mainly targeted at video content generation, AI research and development and other fields.

LongVU
LongVU is an innovative long video language understanding model that reduces the number of video tags through a spatiotemporal adaptive compression mechanism while retaining visual details in long videos. The importance of this technology lies in its ability to process a large number of video frames with only a small loss of visual information within the limited context length, significantly improving the ability to understand and analyze long video content. LongVU outperforms existing methods on multiple video understanding benchmarks, especially on the task of understanding hour-long videos. Additionally, LongVU is able to efficiently scale to smaller model sizes while maintaining state-of-the-art video understanding performance.

mochi-1-preview
This is an advanced video generation model using the AsymmDiT architecture and is available for free trial. It generates high-fidelity video, bridging the gap between open source and closed source video generation systems. Model requires at least 4 H100 GPUs to run.

genmoai
genmoai/models is an open source video generation model that represents the latest progress in video generation technology. The model, named Mochi 1, is a 1 billion parameter diffusion model based on the Asymmetric Diffusion Transformer (AsymmDiT) architecture. It is trained from scratch and is the largest video generation model publicly released to date. It features high-fidelity motion and strong prompt following, significantly bridging the gap between closed and open video generation systems. The model is released under the Apache 2.0 license and users can try it out for free on Genmo’s playground.

Mochi 1
Mochi 1 is a research preview version of an open source video generation model launched by Genmo. It is committed to solving basic problems in the current AI video field. The model is known for its unparalleled motion quality, superior cue following capabilities, and ability to cross the uncanny valley to generate coherent, fluid human movements and expressions. Mochi 1 was developed in response to the need for high-quality video content generation, particularly in the gaming, film and entertainment industries. The product currently offers a free trial, and specific pricing information is not provided on the page.
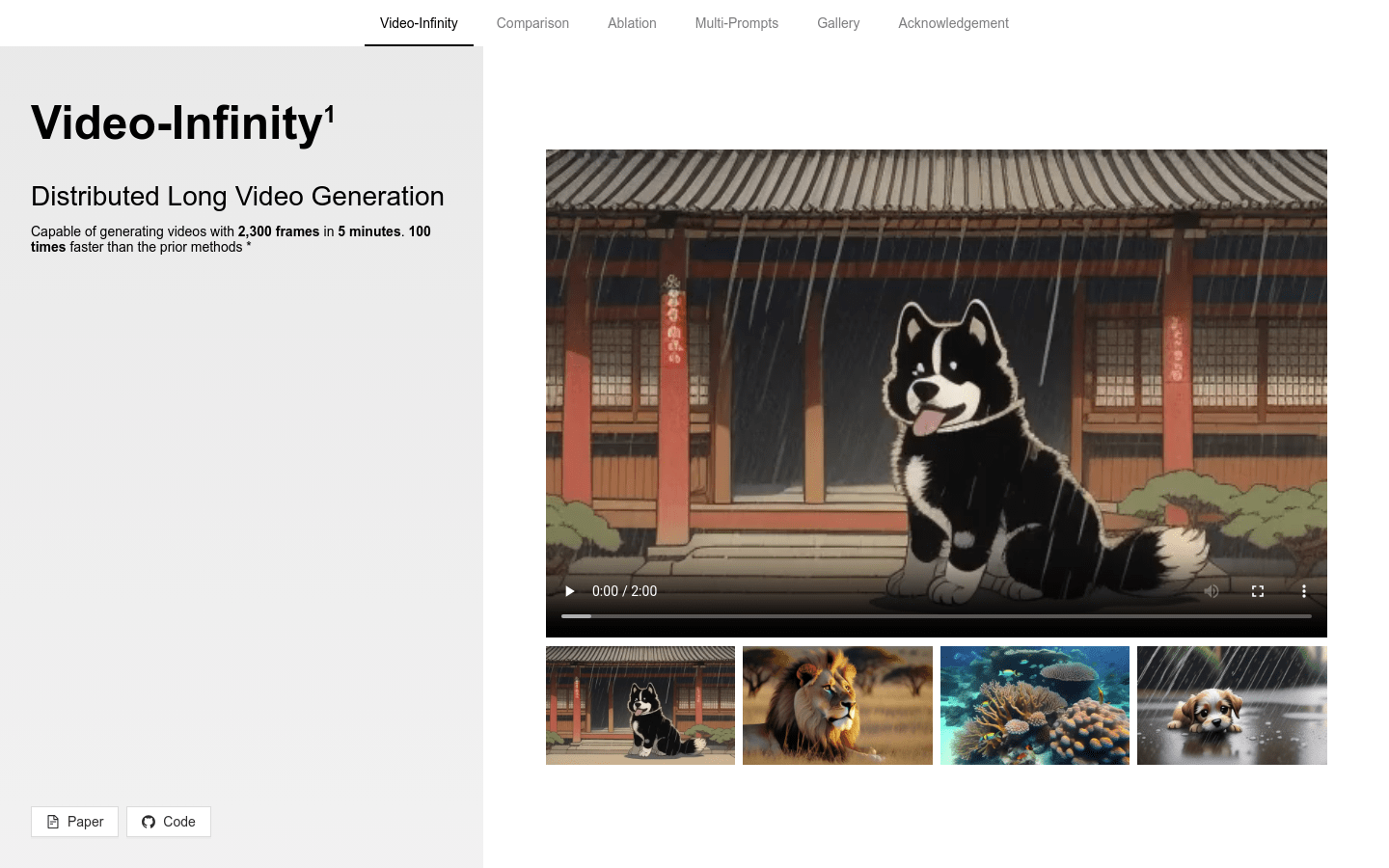
Video-Infinity
Video-Infinity is a distributed long video generation technology that can generate 2300 frames of video in 5 minutes, 100 times faster than previous methods. This technology is based on the VideoCrafter2 model and uses innovative technologies such as Clip Parallelism and Dual-scope Attention to significantly improve the efficiency and quality of video generation.

Etna
The Etna model adopts a Diffusion architecture and combines spatiotemporal convolution and attention layers, allowing it to process video data and understand temporal continuity, thereby generating video content with a temporal dimension. The model is trained on a large video dataset using deep learning technology strategies including large-scale training, hyperparameter optimization and fine-tuning to ensure strong performance and generation capabilities.

Cyanpuppets
Cyanpuppets is an AI algorithm team focusing on generating 3D action models from 2D videos. Their markerless motion capture system completes the capture of more than 208 key points through 2 RGB cameras, supports UE5 and UNITY 2021 versions, and has a latency of only 0.1 seconds. Cyanpuppets supports most skeletal standards and its technology is widely used in games, movies and other entertainment fields.